


Jak algorytmy Machine Learning (ML) pomagają w wykrywaniu i lokalizacji tzw. „cichych usterek” (silent faults) w sieciach komputerowych, zapobiegając pojawieniu się przestojów (outage) w systemach IT.

Producenci urządzeń do budowy sieci komputerowych nowej generacji tworzą je w oparciu o najnowocześniejsze technologie. Stosuje się w nich najnowsze zdobycze w dziedzinie układów mikroprocesorowych, wyposaża w specjalistyczne układy AI do przetwarzania kodu ML (machine learning), a interfejsy przełączników i routerów przesyłają dane z szybkością 400 G. Duże urządzenia modułowe – takie jak np. seria Huawei CE 16800 – można uzbroić nawet w kilkaset takich interfejsów. Dzięki tak zaawansowanym rozwiązaniom oraz postępom w jakości produkcji technologie te pozwalają na osiąganie niezawodności urządzeń na poziomie 0.999996, co tłumaczy się na ich prognozowaną niedostępność rzędu 1.88 min na rok.
Od kilku lat można również zaobserwować w obszarze sieci komputerowych tendencję do standaryzacji oraz prostoty. Fizyczna architektura typu „Leaf&Spine” w sieciach Centrów Przetwarzania Danych (DCN) jest już praktycznie normą, a do sieci kampusowych zmierza ona wielkimi krokami. Warstwa sterująca sieci (control plane) ewoluuje w kierunku SDN oraz unifikacji do 2 podstawowych protokołów EVPN i Segment Routing. Wraz z rozwojem takich technologii i protokołów jak RDMA (Remote Direct Memory Access) czy RoCE (RDMA over Converged Ethernet) w wielu dużych przedsiębiorstwach widać tendencje do rezygnacji z oddzielnej sieci dla Pamięci Masowych (SAN) i wykorzystywania DCN (Data Center Network) jako jedynej „matrycy” (Fabric) łączącej moc obliczeniową z pamięcią masową.
W celu eliminacji jednej z największych (70%1) przyczyn przestojów (outage) w DC – tj. błędów ludzkich – wiele organizacji wdrożyło rozwiązania automatyzacji IT oraz przyjęło najważniejsze metody z kultury organizacyjnej rozwoju oprogramowania DevOps.
Awarie sieci powodem co trzeciego przestoju w pracy data center
Pomimo stosowania najnowocześniejszych technologii do budowy i produkcji sprzętu, upraszczania architektury i protokołów oraz automatyzowania większości etapów cyklu życia sieci komputerowych poważne awarie sieci komputerowej ciągle się zdarzają i stanowią prawie 30% przyczyn przestojów Centrów Przetwarzania Danych2.
Oczywiście po każdym takim poważnym przestoju przeprowadzane są analizy post mortem w celu ustalenia, co było prawdziwą przyczyną i jakie działania prewencyjne należy przedsięwziąć, aby ustrzec się podobnego zdarzenia w przyszłości. Ze statystyk ruchu dotyczących sieci komputerowych klientów firmy Huawei – gromadzonych przez wiele lat – wynika, że w około 62% przypadków przyczyną jest usterka sprzętowa, w 15% błędy konfiguracji, w 8% problemy z niestabilnością protokołów, ale 15% stanowią tajemnicze tzw. „ciche błędy”.

Dowiedz się, jakie korzyści biznesowe możesz osiągnąć wdrażając w swojej firmie sieć bezprzewodową nowej generacji. Weź udział w webinarium z serii #HuaweiTalksIT: Dlaczego warto wybrać Wi-Fi 6 dla swojej firmy? Webinar można obejrzeć w dowolnym czasie.
Więcej informacji na stronie #HuaweiTalksIT.
Ciekawe jednak jest również to, że rozwiązywanie wszystkich problemów spowodowanych przez te tzw. „ciche błędy” zajmuje prawie 80% czasu zespołu obsługi operacyjnej sieci.
Co to są „ciche błędy”? Generalnie rzecz ujmując, są to błędy lub anomalie, które docelowo prowadzą do awarii, ale ich bezpośrednie wystąpienie nie wywołuje „alarmów” w systemach monitorowania i zarządzania siecią. Przykładami mogą być: „chip soft error” (błąd w pamięci RAM procesora sieciowego skutkujący błędnymi instrukcjami), „route flapping” (router ogłasza ścieżkę do tego samego celu na przemian różnymi drogami), „forwarding entry fault”, “FIB table miss”, “ICMP exception”, etc. Największą trudnością w radzeniu sobie z “cichymi błędami” stanowi to, że często problemy te nawarstwiają się powoli i stopniowo, nie wpływając alarmująco na poziomy „wskaźników zdrowia sieci”. Dlatego bardzo trudno je dostrzec i stąd ich nazwa. Nie oznacza to bynajmniej, że nie można nic z tym faktem zrobić.
Sztuczna inteligencja sposobem na zoptymalizowanie warstwy sieciowej
Od pewnego czasu firma Huawei wykorzystuje algorytmy sztucznej inteligencji w rozwiązaniach sieci komputerowych. Robimy to z wykorzystaniem specjalizowanych układów scalonych AI typu Ascend – w samych urządzeniach (AI edge computing) oraz w systemach analitycznych iMaster NCE zasilanych danymi telemetrycznymi z sieci. Jedną z kwestii, które rozwiązujemy za pomocą Sztucznej Inteligencji, jest również problem „cichych błędów”. Wykorzystujemy do tego takie narzędzia jak TSD (time series decomposition), oraz algorytm „f-tree” w połączeniu z algorytmem K-NN (k – nearest neighbours).
Aktualne, realne wyniki z produkcyjnych sieci kilku naszych klientów oraz sieci Huawei są dosyć optymistyczne. Algorytm lokalizuje anomalie i „ciche błędy” z precyzją 95%, stopą błędu 4%, bada ~90% wskaźników odpowiedzialnych ze utratę pakietów (packet loss) – podczas ich przesyłania – i robi to wszystko z szybkością na poziomie minut.
Ale jak to z grubsza działa? Poniżej opiszę w skrócie funkcjonowanie całego procesu, jednak nie będę się zajmował szczegółowym wyjaśnianiem działania samych algorytmów ML tzn., „f-tree” oraz „K-NN” (K-nearest neighbours).
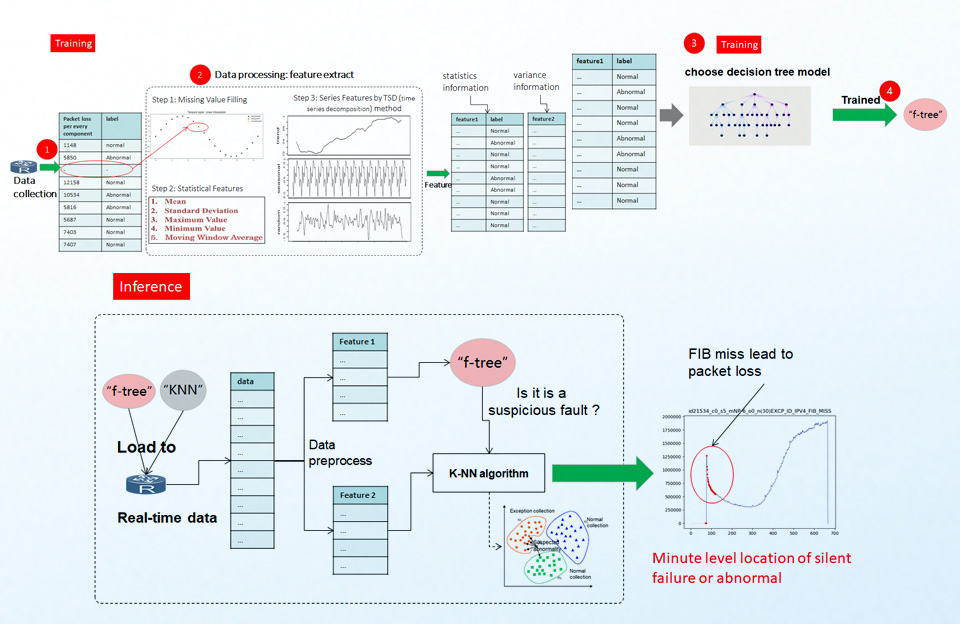
Cały proces przedstawiony jest schematycznie na rysunku powyżej. Proces rozpoczyna się od zbierania i etykietowania (labeling) danych związanych z utratą pakietów dla każdego elementu urządzenia, biorącego udział w procesowaniu pakietu. Potem dla każdej serii obliczane są cechy (features) statystyczne. Główną część tych cech uzyskujemy metodą TSD (time series decomposition) i dotyczą one głównie trendu i sezonowości dla danej serii i poszczególnego elementu. Tworzą one główny wektor cech „feature 1”. Są one etykietowane odpowiednio jako „normalne” i „nieprawidłowe” dla każdej serii. Pozostałe cechy statystyczne (wariancja czy odchylenie standardowe) tworzą następny wektor cechy „feature 2”. W następnym kroku uczymy algorytm „f-tree”, które cechy „feature 1” będą określały zachowanie prawidłowe (np. jak ma wyglądać prawidłowy trend), a które nieprawidłowe. Tak nauczony algorytm, po optymalizacji (wielkość skompilowanego kod nie może być bardzo duża) wgrywamy na procesor urządzenia, wraz z algorytmem K-NN (k-nearest neighbours). W czasie normalnej pracy urządzenia, kiedy podejrzany (anomaly) pakiet zostanie rozpoznany przez algorytm „f-tree” – np. podejrzana jest seria dla tablicy FIB (forwarding information base) – algorytm „K-NN” sprawdzi, czy „zdarzeniu” jest blisko do klastra zdarzeń nieprawidłowych „exception” dla tego komponentu. Wtedy wiemy już, że przyczyną nieprawidłowego zachowania (utraty pakietów) jest tzw. „FIB miss”.
Jest to jeden z wielu obszarów, w których Huawei wykorzystuje Sztuczną Inteligencję do optymalizacji kosztów operacyjnych sieci czy polepszania jakości usług. Pozostałe obszary obejmują między innymi: identyfikację aplikacji (nawet szyfrowanych), oceną jakości konsumpcji usługi (QoE – quality of experience) czy predykcję uszkodzeń komponentów sieciowych.
Jeśli chcesz dowiedzieć się jakie korzyści biznesowe możesz osiągnąć wdrażając sieć bezprzewodową nowej generacji w swojej firmie, to zapraszam Cię do obejrzenia webinaru z serii #HuaweiTalksIT ze mną w roli prelegenta.
Arkadiusz Giedrojć, CTO for IP solutions in Huawei Enterprise Business Group for Nordics and CEE Region
1 – Uptime Institute report 2019
2 – Uptime Institute: 2018 Data Center Industry Survey (data collected from 2016 – 2018)





