

Sztuczna inteligencjaCyberbezpieczeństwoPolecane tematy
Najważniejsze cyberzagrożenia dużych modeli językowych LLM i sposoby przeciwdziałania im
Duże modele językowe (LLM), a właściwie systemy na nich oparte bardzo dynamicznie wdzierają się w nasze życie. Potrafią robić rzeczy niesamowite. I chociaż praktycznie nie rozumiemy, dlaczego tak świetnie działają, to akceptujemy je jako coraz bardzie nieodzowny element naszego dnia codziennego czy pracy.

Mają oczywiście znane wady, takie jak halucynacje, ale rzadko zastanawiamy się na co dzień, co z bezpieczeństwem samych modeli. A wartość takich modeli rośnie jak na przysłowiowych drożdżach. Dobry model, sam w sobie jest cenny, a w przypadku modelu, który został nakarmiony (“fine-tuning”) naszymi korporacyjnymi danymi i tajemnicami, jest bezcennym łupem w rękach konkurencji.
Warto pamiętać, że mimo nowości samej architektury, LLM są do pewnego stopnia tylko „zwykłymi” sieciami neuronowymi z wagami trenowanymi po prostu w bardzo zaawansowany sposób. Oznacza to, że warstwy/macierze modelu są kluczowymi elementami do zrozumienia, jak działa dany model oraz jakie dane można z niego wyciągnąć. Warto przy tym zaznaczyć, że rozmiar pliku popularnego modelu open-source wacha się między 15 a 40GB. A w przypadku samego pliku z wagami dla modelu fine-tune’owanego to jest kilkanaście MB. To niewielki rozmiar w zestawieniu z bogactwem informacji, jakie możemy zdobyć.
Wiedząc, jaki model został użyty, wystarczy “ukraść” tylko ten mały plik zawierający, na przykład w przypadku użycia LoRA, macierze niższego rzędu. Odtworzenie całego modelu w tym przypadku jest kwestią minut.
Dwie drobne uwagi na początek:
- Architektura nowoczesnych LLM jest znacznie bardziej skomplikowana niż to, czego używam w przykładach w tym artykule.
- Z góry przepraszam za mix polsko-angielski, może w przyszłości Bielik, polski model językowy stworzony do przetwarzania i generowania tekstu w języku polskim poradzi sobie lepiej z wynajdowaniem polskich odpowiedników angielskich terminów.
Kategoryzacja zagrożeń związanych z bezpieczeństwem modeli AI
Poniżej proponuje klasyfikację zagrożeń oraz ataków dla modeli LLM. Jest to klasyfikacja, która skupia się na zagrożeniach dla samego modelu. Dla uproszczenia pomijam zupełnie środowisko, w którym model funkcjonuje i które zawiera inne elementy, które zostały wykorzystane do udostępnienia produktu użytkownikom końcowym. Tak samo pomijam zupełnie bezeceństwo samej infrastruktury, w której model działa.
Skupiam się więc na samym modelu, gdzie w raz z rozwojem AI powstało wiele nowych zagrożeń, a stare dobrze znane jeszcze z ML nabrały nowego znaczenia.
Zagrożenia związane z dostępem do modelu (Model Access Threats)
Kradzież Modelu (Model Stealing)- Cel: Odzyskanie funkcjonalności modelu, na przykład poprzez API.
- Przykład: Atak na model GPT-3.5 opisany w [1].
- Cel: Odtworzenie danych treningowych z gradientów modelu.
- Przykład: Odzyskiwanie obrazów z gradientów lub wykorzystanie gradientów modelu, aby znaleźć minimalne zmiany w danych wejściowych (np. w pikselach obrazu), które maksymalizują prawdopodobieństwo błędnej klasyfikacji.
- Cel: Degradacja wydajności modelu w czasie z powodu zmian w rozkładzie danych.
- Przykład: Atakujący mogą celowo wprowadzać zmiany w swoich wzorcach transakcji, aby wywołać dryft modelu. Na przykład, mogą początkowo wykonywać małe, niegroźne transakcje, które stopniowo zmieniają swoje wzorce, aby nie były flagowane jako oszukańcze. Z czasem, model zaczyna akceptować coraz bardziej nietypowe transakcje jako normalne, co otwiera drogę do większych oszustw.
- Cel: Manipulowanie osadzeniami wejściowymi w celu wygenerowania uprzedzonych lub niepoprawnych wyników.
- Przykład: Atakujący mogą manipulować tekstem wiadomości e-mail, aby celowo zmieniać embeddingi w taki sposób, żeby wiadomości spamowe były klasyfikowane jako nie-spam.
Zagrożenia związane z danymi (Data Threats)
Wycieki danych (Data Leakage)- Cel: Ujawnienie danych treningowych modelu.
- Przykład: GPT-2 ujawniający dane osobowe.
- Cel: Wprowadzenie złośliwych danych do zestawu treningowego.
- Przykład: Manipulowanie systemem rekomendacji.
Zagrożenia związane z wejściami/wyjściami modelu (Input/Output Threats)
Ataki poprzez manipulacje danymi wejściowymi (Adversarial Attacks)- Cel: Wprowadzenie zmian w danych wejściowych w celu oszukania modelu.
- Przykład: Szum powodujący błędną klasyfikację obrazu.
- Cel: Usunięcie kluczowych cech z danych wejściowych.
- Przykład: Usunięcie konturów obiektów w obrazach.
- Cel: Odzyskanie informacji o danych treningowych poprzez analizę odpowiedzi modelu.
- Przykład: Odzyskiwanie obrazów twarzy.
Przykłady zagrożeń oraz sposoby przeciwdziałania
Kradzież Modelu (Model Stealing)- Opis zagrożenia: Kradzież modelu polega na odtworzeniu modelu AI poprzez interakcje z jego API. Atakujący może wysyłać zapytania do modelu i analizować odpowiedzi, aby stworzyć nowy model, który naśladuje funkcjonalność oryginalnego modelu.
- Przykład praktyczny: W badaniu „Stealing Part of a Production Language Model” pokazano, jak można uzyskać dużą część funkcjonalności modelu GPT-3.5 Turbo poprzez złośliwe zapytania do API modelu [1].
Przeciwdziałania:
- Rate Limiting: Ograniczenie liczby zapytań do API.
- Monitorowanie wzorców zapytań: Wykrywanie nietypowych zachowań.
- Obfuscation: Utrudnienie procesu odtworzenia modelu przez losowe zakłócenia.
- Watermarking: Dodanie niewidocznych znaczników do odpowiedzi modelu.
- Opis zagrożenia: Modele mogą przypadkowo ujawniać dane treningowe. Gdy są zapytane w określony sposób, mogą wygenerować fragmenty danych treningowych, co prowadzi do wycieków prywatnych informacji.
- Przykład praktyczny: Badania nad GPT-2 wykazały, że model może ujawniać prywatne dane użytkowników w odpowiedziach [4].
Przeciwdziałania:
- Data Anonymization: Anonimizacja danych treningowych.
- Differential Privacy: Wprowadzenie losowych zakłóceń do danych.
- Regular Audits: Regularne audyty danych.
- Limited Data Retention: Ograniczenie czasu przechowywania danych.
- Opis zagrożenia: Atakujący uzyskuje dostęp do gradientów modelu, co pozwala na odtworzenie oryginalnych danych treningowych.
- Przykład praktyczny: Atak gradientowy na model deep learningowy pozwolił na odzyskanie obrazów użytych do treningu [5].
Przeciwdziałania:
- Gradient Noise: Dodanie zakłóceń do gradientów.
- Secure Multi-Party Computation: Bezpieczne obliczenia rozproszone.
- Federated Learning: Trenowanie modeli na danych lokalnych.
- Opis zagrożenia: Ataki adwersarialne polegają na wprowadzaniu drobnych zmian w danych wejściowych, które powodują, że model generuje błędne odpowiedzi.
- Przykład praktyczny: Dodanie szumu do obrazu powodującego błędną klasyfikację przez model AI [6].
Przeciwdziałania:
- Adversarial Training: Trenowanie modelu na zestawach danych z przykładami ataków adwersarialnych.
- Defensive Distillation: Techniki destylacji zwiększające odporność modelu.
- Input Sanitization: Przetwarzanie danych wejściowych w celu usunięcia ataków.
- Opis zagrożenia: Ataki typu data poisoning polegają na wprowadzeniu złośliwych danych do zestawu treningowego modelu.
- Przykład praktyczny: Manipulowanie systemem rekomendacji przez dodanie złośliwych danych do zestawu treningowego [7].
Przeciwdziałania:
- Data Validation: Rygorystyczne sprawdzanie danych przed treningiem.
- Robust Training: Techniki treningowe zwiększające odporność modelu.
- Outlier Detection: Wykrywanie i usuwanie anomalii w danych.
- Opis zagrożenia: Usuwanie cech polega na manipulowaniu danymi wejściowymi, aby usunąć istotne informacje, co może spowodować błędne decyzje modelu.
- Przykład praktyczny: Usunięcie konturów obiektów na obrazach powodujące błędną klasyfikację przez model AI [8].
Przeciwdziałania:
- Feature Squeezing: Redukowanie liczby cech w danych wejściowych.
- Ensemble Methods: Wykorzystanie wielu modeli do podejmowania decyzji.
- Robust Feature Extraction: Ekstrakcja cech odporna na manipulacje.
- Opis zagrożenia: Ataki modelowane wycieki polegają na odzyskiwaniu informacji o danych treningowych poprzez analizę odpowiedzi modelu.
- Przykład praktyczny: Odzyskiwanie obrazów twarzy używanych do treningu modelu rozpoznawania twarzy [9].
Przeciwdziałania:
- Output Perturbation: Dodanie zakłóceń do odpowiedzi modelu.
- Confidence Masking: Ukrywanie informacji o pewności modelu.
- Secure Aggregation: Bezpieczne agregowanie wyników modelu.
Przykład praktyczny
Polecam zapoznanie się ze wszystkimi artykułami, które tutaj przytoczyłem. Teraz chciałbym się skupić na zaprezentowaniu praktycznego przykładu, czyli kradzieży modelu poprzez API.
Ze względu na złożoność architektury i fakt, że nie istnieje jedna unikalna architektura modelu, nie można odzyskać pełnej architektury. Ale można “poprosić” model, aby sam ujawnił nam pewne elementy, takie jak:
- Warstwa projekcji (projection layer)
- Warstwy wyjściowe – to zależy od modelu
- Ukryty prompt(y)
- Hiperparametry (przynajmniej niektóre z nich)
- Ukryte wymiary (“hidden dimensions”)
No dobrze to czy możliwa jest kradzież modeli przez API? To zależy… Ale najpierw zatrzymajmy się na chwilę i zastanówmy się, czym jest „kradzież modelu”.
Kiedy rozważamy ataki kradzieży modelu [Tramèr et al. 2016] [2], dążymy do odzyskania funkcjonalności modelu czarnej skrzynki i optymalizacji pod kątem jednego z dwóch celów [Jagielski et al. 2020][3]:
Dokładność: skradziony model fˆ powinien dopasować wydajność modelu docelowego f na określonym obszarze danych. Na przykład, jeśli celem jest klasyfikator obrazów, możemy chcieć, aby skradziony model dopasował ogólną dokładność modelu docelowego na ImageNet.
Wierność: skradziony model fˆ powinien być funkcjonalnie równoważny modelowi docelowemu f na wszystkich wejściach. To znaczy, dla każdego ważnego wejścia p chcemy, aby fˆ(p) ≈ f (p).
Druga kategoria prowadzi do nadużywania modelu – na podstawie skradzionego modelu f’ możemy przygotować zestawy danych, które wpływają na zachowanie skopiowanego modelu. Uzyskane wyjścia z f’ (p) mogą być użyte do kradzieży własności intelektualnej, uzyskania dostępu do prywatnych danych i tak dalej.
Jedna ważna rzecz! Nie można wyodrębnić dokładnych wag sieci neuronowej tylko na podstawie zapytań/promptów. Możemy wyprowadzić niektóre z wymienionych wcześniej elementów, ale niecałą sieć. To samo dotyczy przypadku funkcjonalnie równoważnego modelu.
Jednak sprawy stają się bardziej interesujące, gdy mamy dostęp do gradientu stochastycznego w formie logbitów dla zapytań, które są zwykle dostępne w API modeli LLM.
API, które ujawniają pełne logproby, pozwalają użytkownikom na dostęp do logarytmicznych prawdopodobieństw (logprobs) dla każdego tokena przewidywanego przez model językowy. Ta funkcja może być szczególnie przydatna w zadaniach takich jak klasyfikacja, gdzie zrozumienie pewności modelu co do każdej klasy (tokena) może być ważne. Analizując je, deweloperzy mogą ustawiać progi pewności lub oceniać, jak pewny jest model w swoich przewidywaniach, co może pomóc w zadaniach takich jak rekomendacja treści czy redukcja halucynacji w systemach opartych na architekturze RAG (Retrieval Augmented Generation).
Podejście: modele liniowe
Najpierw porozmawiajmy o modelach liniowych. Rozważmy model liniowy: f(x) = W.x
Istnieją dwa sposoby na odtworzenie funkcji f():
Uczenie maszynowe – moglibyśmy spróbować wytrenować model na parach (xi, f(xi)), lub
- Możemy rozważyć bardziej matematyczne podejście, przygotowując zapytania w inteligentny sposób:
f[100…0] = W0
f[010…0] = W1
W drugim podejściu możemy bezpośrednio odtworzyć model liniowy f() tylko poprzez przygotowanie odpowiednich zapytań!
Sieć bez ukrytych warstw
To raczej trywialny przykład, ale ważne jest, aby zrozumieć całą logikę. Załóżmy, że mamy bardzo prostą sieć, jak pokazano na rysunku 1.
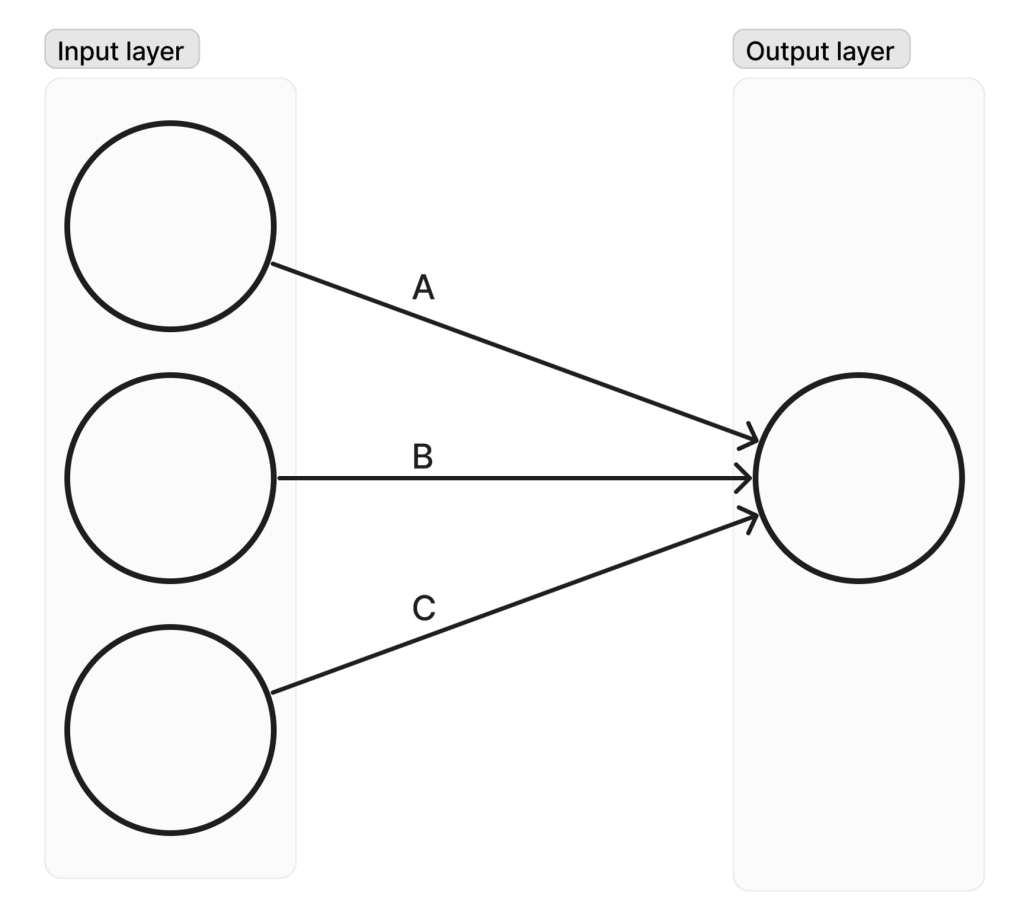
W tym przypadku, przesyłając do modelu zapytanie z przygotowanym wejściem [100], możemy bezpośrednio odczytać każdą z wag na neuronach wyjściowych: A, B, C – jak pokazano na rysunku 2 dla wagi A.
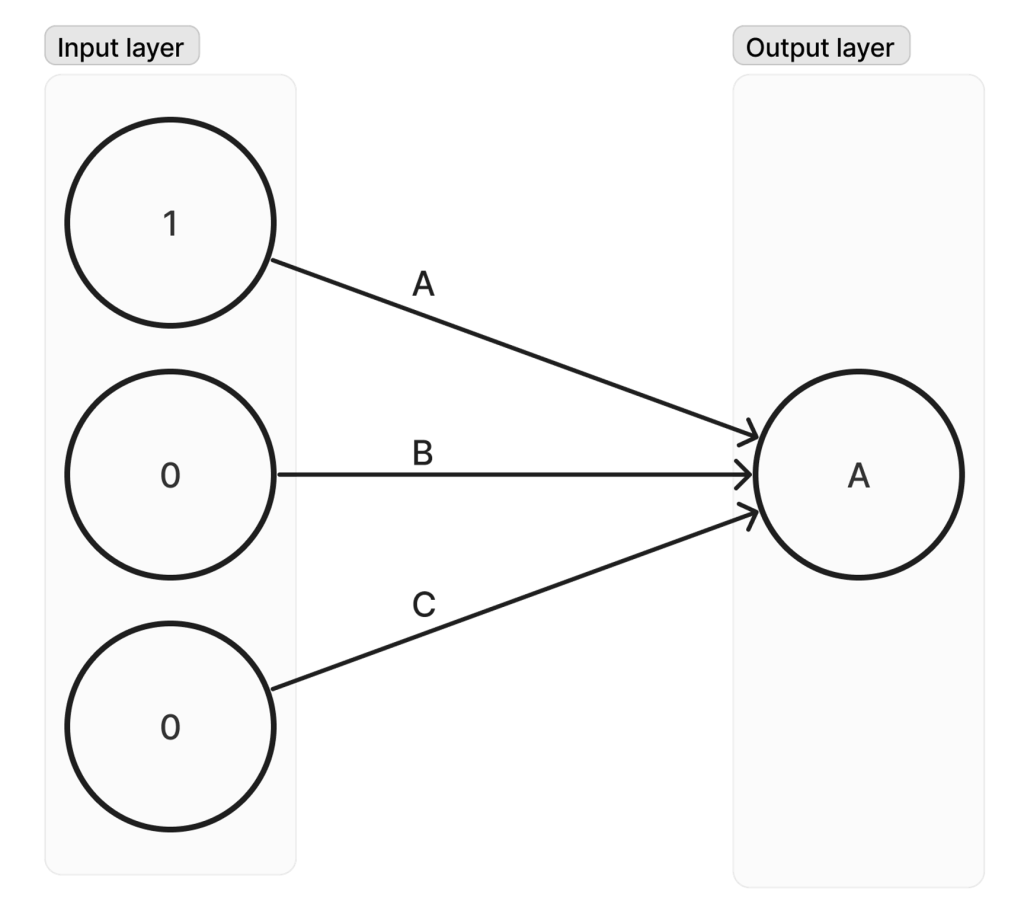
Więc w zasadzie, manipulując wejściem, możemy odzyskać wszystkie wagi w modelu bez posiadania jakiejkolwiek wcześniejszej wiedzy o modelu. Ważne jest, aby zauważyć, że nie robimy losowych zapytań, próbując zgadnąć model!
Sieć z jedną ukrytą warstwą
Teraz omówmy bardziej skomplikowany przypadek, który pokaże zasadę dalszego podejścia do ekstrakcji modelu. Załóżmy, że mamy jedną ukrytą warstwę, jak pokazano na rysunku 3.
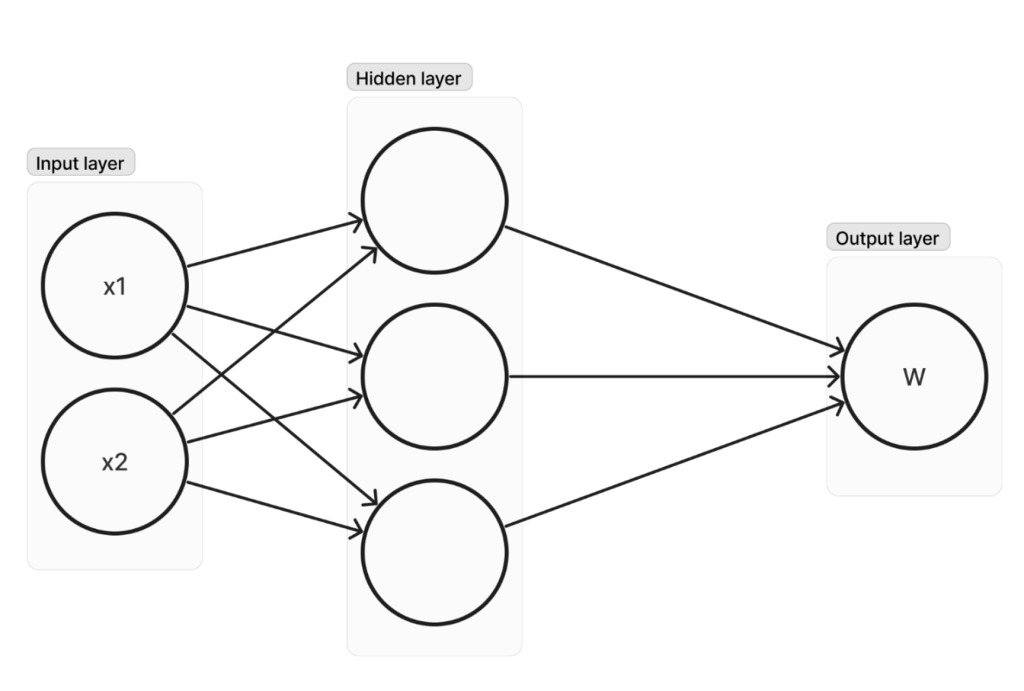
Ważne jest zrozumienie graficznej reprezentacji takich sieci. Wyglądałoby to następująco (zakładając, że sieć używa funkcji ReLU):
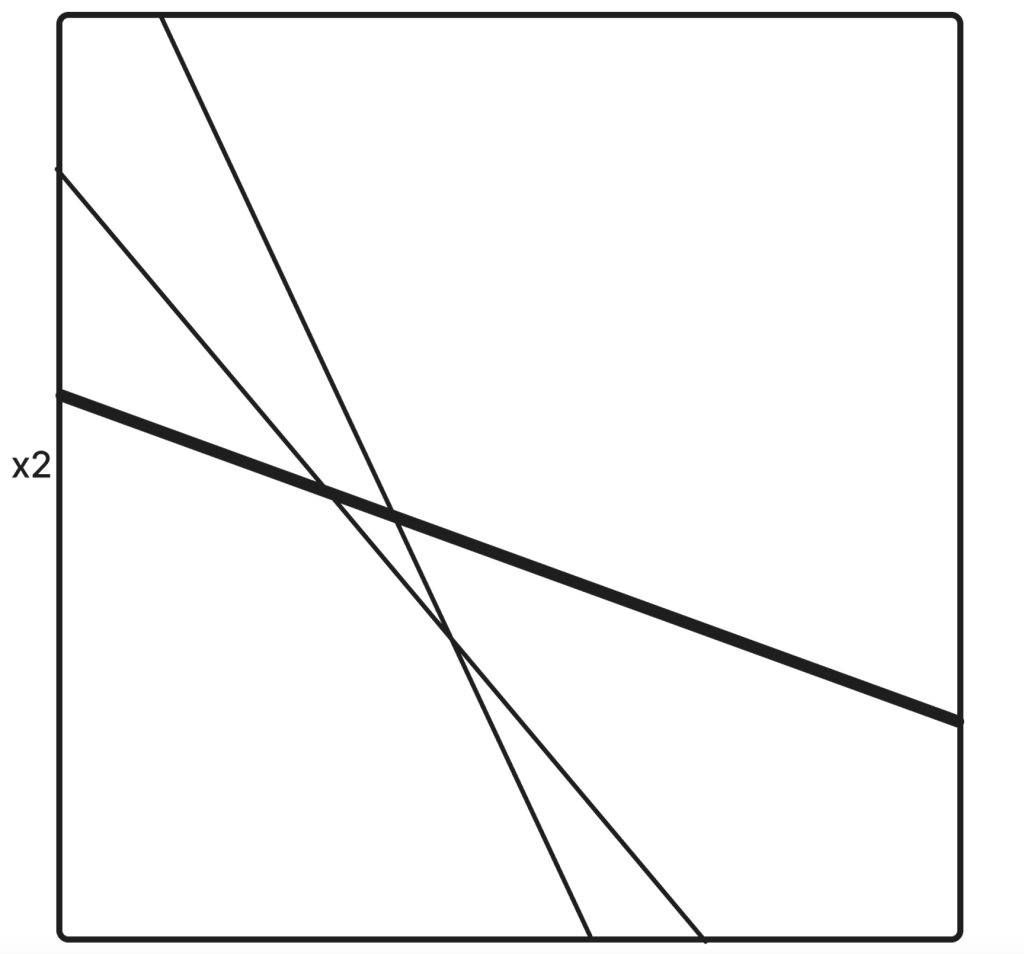
Znów linie reprezentują punkty w przestrzeni, gdzie gradient zmienia swój znak. Linie te nazywane są krytycznymi hiperpłaszczyznami i całkowicie determinują, jak zachowuje się sieć. Każda linia reprezentuje jeden neuron z jego gradientową funkcją aktywacji.
Znów, przygotowując zapytania w taki sposób, aby znaleźć punkt na tych hiperpłaszczyznach (co oznacza „0” wagę na danym neuronie), możemy odzyskać dwie pozostałe wagi w ukrytej warstwie.
Można to zrobić, ponieważ zakładając, że mamy punkt znajdujący się na hiperpłaszczyźnie, poprzez niewielkie zmiany na wejściu, możemy odzyskać proporcje wag na dwóch pozostałych neuronach w naszej sieci! Jest to wykonalne, jednak nie jest to takie proste.
Wnioski
W tym artykule postarałem się przedstawić krótki przegląd zagrożeń dla modeli LLM wraz z przykładami. Artykuł powinien być dobrym wprowadzeniem do lepszego zrozumienia tematu bezpieczeństwa modeli AI, absolutnie nie wyczerpuje tematu! Gorąco zachęcam do przestudiowania podanych źródeł.
Warto zauważyć, że oba zaprezentowane w przykładach podejścia nie wymagają żadnych dodatkowych informacji, tylko dostępu do wejść/wyjść modelu. Zostało to pokazane w praktyce na aktualnie funkcjonujących i dostępnych dla użytkowników modelach. Mnie to odrobinkę przeraża 😉
Znaczenie tego obszaru badan będzie tylko rosło z czasem wraz z upowszechnianiem się rozwiązań AI.
Antares Gryczan, Executive Director, PFR Operacje
Źródła:- [1] “Stealing Part of a Production Language Model“ — Nicholas Carlini, Daniel Paleka, Krishnamurthy Dj Dvijotham, Thomas Steinke, Jonathan Hayase, A. Feder Cooper, Katherine Lee, Matthew Jagielski, Milad Nasr, Arthur Conmy, Eric Wallace, David Rolnick, Florian Tramèr, March 2024.
- [2] “Stealing Machine Learning Models via Prediction APIs” — Florian Tramèr, École Polytechnique Fédérale de Lausanne (EPFL); Fan Zhang, Cornell University; Ari Juels, Cornell Tech; Michael K. Reiter, The University of North Carolina at Chapel Hill; Thomas Ristenpart, Cornell Tech, August 2016
- [3] “High accuracy and high fidelity extraction of neural networks” In USENIX Security Symposium — Jagielski, M., Carlini, N., Berthelot, D., Kurakin, A., and Papernot, N. , 2020
- [4] “Scalable Extraction of Training Data from (Production) Language Models” – Nicolas Carllini with team, June 2021
- [5] “Deep Leakage from Gradients” – Ligeng Zhu, Zhijian Liu, Song Han, Dec 2019
- [6] “Google’s Cloud Vision API Is Not Robust To Noise” – Hossein Hosseini, Baicen Xiao and Radha Poovendran, Jul 2017
- [7] “Poisoning Attacks against Recommender Systems: A Survey” – Zongwei Wang, Min Gao, Junliang Yu, Hao Ma, Hongzhi Yin, Shazia Sadiq, Jan 2024
- [8] “Inst-Inpaint: Instructing to Remove Objects with Diffusion Models” – Ahmet Burak Yildirim, Vedat Baday, Erkut Erdem, Aykut Erdem, and Aysegul Dundar
- [9] “Variational Model Inversion Attacks” – Kuan-Chieh Wang, Yan Fu, Ke Li, Ashish Khisti, Richard Zemel, Alireza Makhzani, Jan 2022





