

CyberbezpieczeństwoSztuczna inteligencja
DeepSeek-R1 podatny na szybkie ataki – słabym punktem modelu jest proces myślowy
Grupa specjalistów Trend Micro przeprowadziła badanie dotyczące podatności modelu DeepSeek-R1 na ataki wykorzystujące jego proces myślowy – Chain of Thought (CoT), a także analizę skuteczności różnych technik ataku. Do badania wykorzystano serię ataków typu prompt injection. Charakterystyczną cechą DeepSeek-R1 jest bezpośrednie udostępnianie rozumowania CoT, co można wykorzystać do szybkich ataków.
![]()
Coraz powszechniejsze wykorzystanie rozumowania łańcuchowego (CoT) oznacza nową erę dla dużych modeli językowych. Rozumowanie to zachęca model do przemyślenia odpowiedzi przed jego ostateczną reakcją. CoT stało się kamieniem węgielnym dla najnowocześniejszych modeli rozumowania – w tym O1 i O3-mini firmy OpenAI i właśnie DeepSeek-R1 – z których wszystkie trenowane są do stosowania tego rozumowania.
Jak się okazuje, charakterystyczną cechą DeepSeek-R1 jest bezpośrednie udostępnianie rozumowania CoT. Eksperci Trend Micro przeprowadzili serię szybkich ataków na 671-miliardowy parametr DeepSeek-R1 i odkryli, że informacje te można wykorzystać do znacznego zwiększenia wskaźników powodzenia ataków. Model DeepSeek-R1 ujawnia swój proces myślowy w tagach <think>, co umożliwia atakującym analizowanie logiki modelu i tworzenie skuteczniejszych ataków.
Badacze Trend Micro użyli narzędzi red team typu open source, takich jak Garak firmy NVIDIA – zaprojektowanych do identyfikowania luk w zabezpieczeniach LLM poprzez wysyłanie zautomatyzowanych ataków natychmiastowych – wraz ze specjalnie opracowanymi atakami natychmiastowymi, aby przeanalizować odpowiedzi DeepSeek-R1 na różne techniki i cele ataków.
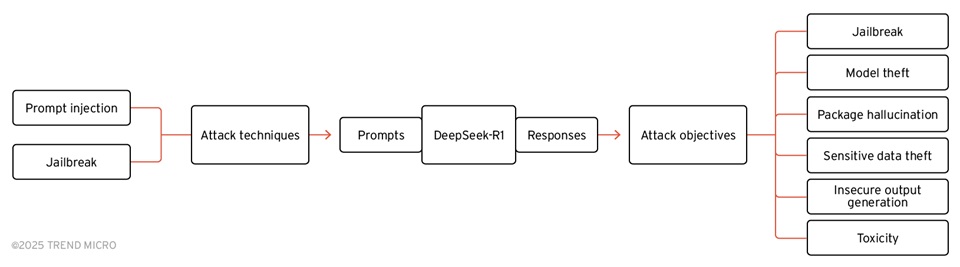
Testy wykazały, że ataki wykorzystujące prompt injection i jailbreak mogą skutecznie omijać zabezpieczenia modelu.
Najbardziej podatne obszary:
- Kradzież danych – możliwość ujawnienia wrażliwych informacji, w tym np. kluczy API.
- Niebezpieczne generowanie outputu – model może nieświadomie podawać dane, które mogą być wykorzystane w ataku.
Zalecenia dotyczące bezpieczeństwa:
- Filtracja tagów <think> w chatbotach, by ograniczyć ujawnianie logiki modelu.
- Wdrożenie strategii „red teaming” i testów penetracyjnych, aby stale monitorować zagrożenia.





