

Artykuł z magazynu ITwizArchitektura ITPolecane tematy
Hadoop, czyli przetwarzanie rozproszone w open source
W ostatnich latach jednym z najmodniejszych i najczęściej wspominanych terminów w branży IT jest „Big Data”. De facto jednak każda epoka ma swoje „Big Data”, czyli moment, kiedy aktualnie znane metody przestają rozwiązywać powstające problemy i zaczynamy marzyć. Prędzej czy później przychodzą rozwiązania, które umożliwią realizację tych pragnień…

Apetyt rośnie w miarę jedzenia, więc kiedy kończy się miejsce na dysku twardym, trzeba kupić nowy. Jednak w pewnym momencie kupujemy największy dostępny na rynku dysk, dokładamy kolejny i kolejny, i… okazuje się, że nasza macierz nie ma więcej miejsca na dyski, a rozwój technologii postępuje zbyt wolno. Obecnie szacuje się, że ilość danych cyfrowych zgromadzona w internecie sięga dziesiątek lub setek exabajtów!
Skopiujmy internet!
Pewnie każdy z nas spotkał się z żartem dotyczącym skopiowania internetu. Okazuje się jednak, że pomysł ten pozwolił zbudować potęgę Google. W połowie lat 90. XX wieku powstawały zarysy koncepcji dzisiejszego Big Data. Google – aby zapewnić bezkonkurencyjną jakość usług – postanowiła zaindeksować treść stron www. Jednak potrzebowała do tego niewyobrażalnych – jak na tamte czasy – zasobów i przestrzeni dyskowej.
Ponieważ firma nie była wtedy tak bogata jak dziś, zamiast inwestować w topowy sprzęt, opracowała własne rozwiązanie i tak powstał GFS (Google File System), który wykorzystywał koncepcję przetwarzania i przechowywania danych w systemie rozproszonym DFS (Distributed File System). Do pełnego sukcesu potrzebny był jeszcze skuteczny mechanizm dostępu do danych, czyli Map-Reduce.
Podstawowe cele, które osiągnięto dzięki koncepcji GFS i Map-Reduce, to:
- – redukcja kosztów,
- – zwiększenie przestrzeni dyskowej,
- – zrównoleglenie operacji przetwarzania danych,
- – dostarczenie wyższej niż kiedykolwiek wcześniej skalowalności,
- – zapewnienie wysokiej dostępności rozwiązań,
- – uniezależnienie od producenta rozwiązań sprzętowych.
Open source z odsieczą!
Po udostępnieniu informacji o GFS przez Google, organizacja Apache powołała projekt stworzenia analogicznego rozwiązania objętego licencją typu open source, które dziś – obok serwera www – jest najczęściej spotykanym rozwiązaniem sygnowanym logo Apache. Jego sukces był błyskawiczny i mimo że rozwiązanie wciąż jest rozwijane i jeszcze niedoskonałe, już zyskało ogromną popularność. Mowa o Hadoop, wokół którego uruchomionych zostało już ponad 2500 projektów open source. Skąd tak wielki sukces tego projektu?
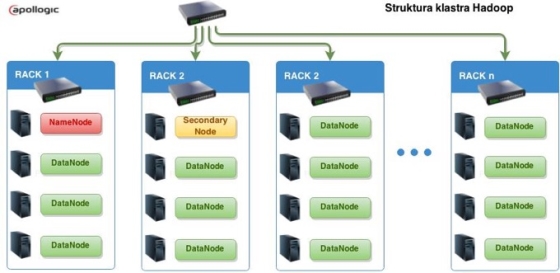
Hadoop jest systemem rozproszonego przechowywania i przetwarzania plików. Dane są rozproszone na wielu serwerach i dzielone na bloki, które zostają rozdystrybuowane pomiędzy węzłami. Natomiast metadane, pozwalające uzyskać dostęp do określonego fragmentu pliku, przechowywane są w pamięci operacyjnej serwera NameNode.
Charakterystykę środowiska można opisać jednym zdaniem. Hadoop jest systemem rozproszonego przechowywania i przetwarzania plików. Dane są rozproszone na wielu serwerach i dzielone na bloki, które zostają rozdystrybuowane pomiędzy węzłami. Natomiast metadane, pozwalające uzyskać dostęp do określonego fragmentu pliku, przechowywane są w pamięci operacyjnej serwera NameNode.
Aby zabezpieczyć dane przed awarią pojedynczego węzła, są one replikowane na kilku węzłach, standardowo trzech. Natomiast aby zapobiec awarii przełącznika sieciowego, większe klastry dzieli się na racki. W przypadku awarii racka, w którym znajduje się NameNode, jego rolę przejmuje SecondaryNode. Dostęp do plików jest realizowany przez YARN (YetAnother Resource Negotiator). Jest to druga generacja MapReduce, nazywana również MapReduce 2.0.
Czym NIE jest Hadoop?
System operacyjny? Hadoop jest platformą uruchamianą w systemie Linux. Jednak w ostatnich miesiącach – w związku z nawiązaniem współpracy przez firmy Hortonworks oraz Microsoft – dostępna jest również wersja działająca w systemie MS Windows.
System plików zgodny z POSIX? POSIX (Portable Operating System Interface for Unix) jest standardem zgodności dla systemów Unix. System plików HDFS wspiera większą część standardu, jednak nie wszystkie komendy są obsługiwane. Ponadto system plików nie jest dostępny z poziomu systemu operacyjnego, choć od pewnego czasu dostępne są bramki NFS, umożliwiające odwzorowanie HDFS w systemie plików systemu operacyjnego.
Serwer NAS (Network Attached Storage)? Mogłoby się wydawać, że tak zaprojektowany system nadaje się idealnie do tego rodzaju zastosowań – niskie koszty rozbudowy, praktycznie nieograniczona przestrzeń, odporność na awarie sprzętu… Stop! Hadoop jest zaprojektowany do przechowywania ogromnych plików, ale nie do przechowywania ogromnej ilości plików. Metadane przechowywane są w pamięci operacyjnej serwera NameNode, więc ilość plików przetrzymywanych w HDFS jest ograniczona. Drugim problemem jest bezpośredni dostęp z poziomu systemu operacyjnego, choć ten problem może być rozwiązany za pomocą bramki NFS.
Trzeci problem możemy napotkać podczas próby współbieżnego dostępu do plików. Choć jest jeden wyjątek – jedna z dystrybucji (MapR) wykorzystuje zmodyfikowaną architekturę Hadoop, eliminującą serwer NameNode. Jego miejsce zajmują serwery CLDB, które nie są już tzw. single point of failure, nie wymagają ogromnych ilości pamięci RAM do przechowywania metadanych i są dostępne wielopunktowo. W przypadku odcięcia jednego lub kilku serwerów CLDB działa zasada quorum. W połączeniu z dodaniem funkcjonalności snapshot, znanej z macierzy klasy enterprise (dostępne w wersji M7) oraz dojrzałej już bramki NFS, MapR staje się funkcjonalną i niezawodną macierzą dyskową.
Hadoop jest zaprojektowany do przechowywania ogromnych plików, ale nie do przechowywania ogromnej ilości plików. Metadane przechowywane są w pamięci operacyjnej serwera NameNode, więc ilość plików przetrzymywanychw HDFS jest ograniczona. Drugim problemem jest bezpośredni dostęp z poziomu systemu operacyjnego, choć ten problem może być rozwiązany za pomocą bramki NFS. Trzeci problem możemy napotkać podczas próby współbieżnego dostępu do plików.
System zarządzania relacyjną bazą danych (RDBMS)? Hadoop nigdy nie był i nigdy nie będzie systemem RDBMS. Ze względu na powszechność tych systemów w procesie przetwarzania danych, często spotykam się z wyobrażeniem, że Hadoop jest bazą danych. NIE jest! Hadoop jest platformą składającą się z rozproszonego systemu plików (HDFS) oraz środowiska umożliwiającego programowanie rozproszone (MapReduce).
Baza danych NoSQL? Skoro nie relacyjna baza danych, to na pewno baza NoSQL? Też nie. Hadoop nie zachowuje własności ACID (Atomicity, Consistency, Isolation, Durability) i nigdy nie będzie tego robił. Dane przechowywane są w plikach, jak w systemie operacyjnym. Natomiast istnieją bazy danych NoSQL działające w ekosystemie Hadoop, takie jak HBase – kolumnowa baza danych, choć nie zachowuje w pełni własności ACID, dostarcza zestaw operacji CRUD (Create, Read, Update, Delete). Dostępne są również rozwiązania umożliwiające dostęp do danych w HDFS z wykorzystaniem języka SQL (Hive, Impala, Spark), jednak to długa historia.
Interaktywna aplikacja z przyjaznym interfejsem? Nic bardziej mylnego. Linux, CLI i czarne okienka – kiedy pracuję w środowisku Hadoop, koledzy uważają, że przypominam prawdziwego hakera. Nie ma przyjaznego Drag’n’Drop, wirtualnych klocków i kreatorów – jest środowisko programistyczne. Istnieją interfejsy web (Hue), konektory ODBC/JDBC umożliwiające korzystanie z narzędzi ekosystemu Hadoop z poziomu aplikacji ETL lub Business Intelligence, ale nadal potrzebna jest solidna porcja wiedzy, aby skutecznie korzystać z tej technologii. Jednak, jak pokazują ostatnie lata, mimo trudności, korzystanie z Hadoop jest nadal bardzo opłacalne.
Hurtownia danych? W tym punkcie jest trochę miejsca na dyskusję. Cały ekosystem jest i nie jest hurtownią danych. Na pewno w klasycznych systemach hurtowni, opartych na relacyjnych bazach danych, znajdziemy znacznie więcej, dużo bardziej dojrzałych i zaawansowanych narzędzi. Dedykowane systemy in-memory będą znacznie wydajniejsze, analizy i generowanie raportów będą trwały krócej. Ale w Hadoop przestrzeń jest tańsza, a analizy na bardzo dużych zbiorach danych mogą zostać zrównoleglone. Nie ma róży bez kolców – dziś Hadoop nie zastąpi w pełni hurtowni danych, ale może rozszerzyć jej funkcjonalność i umożliwić analizę danych, która dotychczas była niewykonalna ze względu na koszty lub złożoność przetwarzania.
Bezpieczna składnica danych? Dane w Hadoop są bezpieczne, bo niestraszna im awaria sprzętu. Niestety, przechowywanie szczególnie wrażliwych danych nie jest wskazane z uwagi na brak zaawansowanych systemów zarządzania uprawnieniami i dostępem. Choć prace nad odpowiednimi systemami trwają i z pewnością będą one dostępne w ciągu kilku miesięcy.
Szybka platforma obliczeniowa? MapReduce nadaje się świetnie do przetwarzania wielowątkowego. Jednak należy pamiętać, że nie każda operacja będzie wykonana efektywnie. Rozwiązanie niektórych problemów może zająć sporo czasu. Bardziej dojrzałe systemy, takie jak relacyjne bazy danych i hurtownie danych, mają zaimplementowane optymalizatory, dzięki którym poradzą sobie z wieloma problemami szybciej.
Dane w Hadoop są bezpieczne, bo niestraszna im awaria sprzętu. Niestety, przechowywanie szczególnie wrażliwych danych nie jest wskazane ze względu na brak zaawansowanych systemów zarządzania uprawnieniami i dostępem. Choć prace nad odpowiednimi systemami trwają i z pewnością będą one dostępne w ciągu kilku miesięcy.
Hadoop co to jest i do czego można wykorzystać?
Technologia jest nowa i wymaga umiejętności niskopoziomowych. Nie zastąpi aktualnie wykorzystywanych systemów, ale nie ma sobie równych, jeśli:
- 1. Potrzebujemy redukcji kosztów przechowywania danych. Koszt 1 GB przestrzeni w klasycznych hurtowniach danych jest nawet kilkuset razy wyższy niż w HDFS. Hadoop, jako projekt open source, nie wymaga opłat licencyjnych za oprogramowanie, płatnych licencji systemu operacyjnego, licencji dla użytkowników oraz drogich platform sprzętowych, ponieważ jest zaprojektowany do pracy na zwykłych serwerach do tzw. powszechnego użytku.
- 2. Potrzebujemy przechowywać dane „na zawsze”. System jest skalowalny i inwestycję można rozkładać w czasie, rozszerzając farmę wraz ze wzrostem zapotrzebowania. Rozbudowa jest prosta i niedroga.
- 3. Przetwarzamy różne typy danych. Ponieważ HDFS jest po prostu systemem plików, możliwe jest przechowywanie danych w dowolnej postaci. W przeciwieństwie do relacyjnej bazy danych, nie jesteśmy już ograniczeni strukturą tabel, a dane mogą być przechowywane w postaci plików tekstowych, dokumentów, obiektów itp. Poza tym ekosystem Hadoop zawiera narzędzia, które pozwalają przetwarzać dane jednocześnie z wykorzystaniem składni SQL i dowolnego języka programowania. Nadaje się świetnie do przetwarzania ciągłego tekstu, plików semistrukturalnych czy danych maszynowych.
- 4. Potrzebujemy ogromnych plików. Praktycznie nie ma ograniczeń związanych z wielkością plików przechowywanych w HDFS. System został stworzony po to, aby przetwarzać pliki o niewyobrażalnych rozmiarach. Możliwe jest przechowywanie i przetwarzanie plików, które nie zmieszczą się w żadnej pamięci operacyjnej, na żadnym twardym dysku czy macierzy. Pliki o rozmiarach kilku petabajtów nie są już przeszkodą.
- 5. Potrzebujemy zrównoleglenia operacji. Średniej wielkości klastry mają do dyspozycji kilkaset TB pojemności dyskowej, kilkaset GB pamięci RAM i kilkaset rdzeni procesora. Każda aplikacja może po nie sięgnąć.
- 6. Aby nie wyrzucać „mniej ważnych danych”. Dane, które trzeba usunąć lub zarchiwizować na taśmach, aby zapewnić ciągłość pracy hurtowni, mogą być archiwizowane w HDFS. Dzięki temu są dostępne bez kosztownego procesu odtwarzania. Można też zbierać dane, co do których nie ma pewności, czy są przydatne. Możliwe, że kiedyś dzięki nim zostaną odkryte nowe zależności.
- 7. Aby być gotowym na przyszłość. Niewątpliwie – systemy rozproszone są przyszłością IT. Warto zrobić ten krok w przyszłość, ponieważ już dziś jest niewielu specjalistów, którzy potrafią pracować z ekosystemem Hadoop, a zapotrzebowanie na nich wciąż wzrasta. Jest to odpowiedni czas, aby zacząć od małego klastra składającego się z kilku węzłów, a następnie skalować rozwiązanie wraz ze wzrostem zapotrzebowania.
Marcin Siudziński jest BI/Big Data Consultantem w Apollogic.





