Artykuł z magazynu ITwizAdvertorialCIOPolecane tematy
Monitoring aplikacji w świecie mikrousług i rozwiązań klasy HPC
Advertorial
Advertorial
Nie jest możliwe osiągnięcie i utrzymanie wysokiej wydajności bez bieżącego nadzoru i szybkiej diagnostyki systemów. Stąd istotne jest przybliżenie problemów i wymagań, które niesie High Performance Computing, a w szczególności tzw. konteneryzacja. Rozwiązaniem może być Next Generation Monitoring.
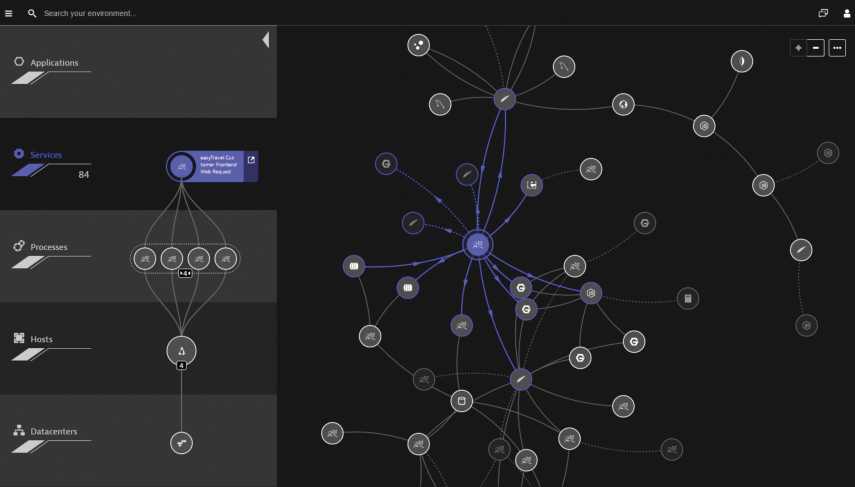 Przykład użycia technologii SmartScape do wizualizacji zależności pomiędzy usługą biznesową, aplikacją i infrastrukturą
Przykład użycia technologii SmartScape do wizualizacji zależności pomiędzy usługą biznesową, aplikacją i infrastrukturą
Cały świat z zainteresowaniem obserwuje sukcesy firm, takich jak Facebook, Twitter, LinkedIn, a ostatnio – Uber czy AirBnB. Ich sukces w dużej mierze opiera się na wysokiej wydajności i dostępności usług. Sukcesu tego nie byłoby jednak bez sprawnych aplikacji, które w wielu przypadkach nie obyłyby się bez kontenerów i mikrousług.
Przykładowo, Uber – według ostatnich statystyk z września br. – ma: 200 tys. kierowców, 8 mln użytkowników i 2 mld transakcji; ma provisioning aplikacji funkcjonujący na bazie Dockera i Mesos. Zapewnia to im spójność konfiguracji i doskonałą skalowalność. Jednym z kluczowych elementów tego projektu jest monitoring i wykorzystywane do tego narzędzie Argos. Umożliwia ono detekcję anomalii, bez której nie jest możliwe zarządzanie wydajnością i dostępnością środowiska aplikacyjnego Ubera. Argos jest uszytym na miarę garniturem, który dobrze funkcjonuje na potrzeby Ubera. Mimo że nie każda firma może sobie pozwolić na komfort napisania i utrzymania takiego rozwiązania, to na rynku dostępne są już uniwersalne rozwiązania wspierające nowej generacji monitoring środowisk aplikacyjnych.
Problem z monitoringiem w kontekście rozwiązań HPC
Nowego podejścia wymaga monitorowanie sprawności działania aplikacji w kontekście nowych architektur aplikacyjnych i przetwarzania wysokiej wydajności. W klasycznej architekturze można obserwować sezonowość metryk oraz trendy. Można też stosunkowo łatwo wyeliminować 90% tzw. false-positives, co jest dużym usprawnieniem dla administratorów. Z kolei konteneryzacja, która jest dobrodziejstwem dla deweloperów, dla operacji może być sporym wyzwaniem, jeśli chodzi o możliwość kontrolowania wydajności i wpływu tej części na pozostałe elementy architektury aplikacji.
Czym zatem jest wykrywanie anomalii? Jest to sposób na wykrywanie istotnego sygnału (faktycznego problemu) w niejednorodnej grupie metryk. W kontekście systemów monitorujących jest to cecha, która pozwala im na wykrywanie niespodziewanych wartości, dla przypadków z grupy outlierów, a następnie powiadamianie o przekroczeniach wartości. Taka analiza, w monitoringu aplikacji, powinna dotyczyć co najmniej czterech obszarów: użycia systemu; obserwowanego poziomu błędów; wydajności transakcji oraz User Experience.
Systemy są trwałe. Natomiast komponenty są powoływane i tracą żywotność bardzo szybko, a czas ich przydatności może być mniejszy niż standardowa częstotliwość próbkowania systemów monitorujących, czyli 1–15 min per pomiar danych. Teoretycznie możliwe jest zwiększenie częstotliwości pomiarów, ale wywoła to kolejną lawinę w postaci ilości danych, które należy przetworzyć – nie rozwiąże to podstawowego zagadnienia, jakim jest detekcja rzeczywistych problemów i analiza wzajemnego wpływu komponentów w warunkach ich nietrwałości, przy jednoczesnym założeniu braku cykliczności zbieranych metryk. W efekcie, tradycyjny monitoring i alertowanie z wykorzystaniem statycznych progów, analizą oscylacji (np. state flapping), statystyczną analizą rozkładu danych (np. potrójne odchylenie standardowe od średniej) nie dają szans na wykrywanie anomalii w działaniu systemów.
Cechy typowe dla monitoringu „klasycznych” architektur:
• analiza systemu na bazie metryk, w których wiodącą rolę ma część infrastrukturalna;
• adaptacja do zmian wymagająca dłuższego czasu na przestrojenie systemu;
• brak analizy semantyki; silosowe podejście, często bez perspektywy end-to-end;
• wybiórcze podejście do danych: sampling transakcji, fragmentaryczny user-experience.
Cechy wymagane w przypadku monitoringu aplikacji opartych na mikrousługach:
• analiza systemu z wiodącą rolą aplikacji i perspektywą użytkownika końcowego;
• bardzo duża łatwość wdrożenia – dostępne mechanizmy wspierające automatyzację tego procesu;
• AI i analiza semantyki – bardzo szybka adaptacja do zmian* w architekturze, z uwzględnieniem czasu życia komponentów;
• zaawansowane mechanizmy predykcji problemów i alertowania, uwzględniające specyfikę zachowań tzw. kontenerów;
• istotna rola perspektywy User Experience w określeniu działania systemu.
* Ta grupa rozwiązań charakteryzuje się dużo większą dynamiką zmian i wsparciem najnowszych technologii – np. Angular.js, OpenShift, Docker, Play, Scala, Akka, NginX, Redis, MongoDB, Ruby itp. – których trudno szukać w klasycznych rozwiązaniach
Czym zatem jest wykrywanie anomalii? Jest to sposób na wykrywanie istotnego sygnału (faktycznego problemu) w niejednorodnej grupie metryk. W kontekście systemów monitorujących jest to cecha, która pozwala im na wykrywanie niespodziewanych wartości, dla przypadków z grupy outlierów, a następnie powiadamianie o przekroczeniach wartości. Taka analiza, w monitoringu aplikacji, powinna dotyczyć co najmniej czterech obszarów: użycia systemu; obserwowanego poziomu błędów; wydajności transakcji oraz User Experience. Należy zaznaczyć, że detekcja anomalii jest stosunkowo tania, jeśli jest wykonywana online (one pass if data arrives). Podejście ad hoc – analiza post factum – jest zbyt kosztowna, aby mogła być wykonywana interaktywnie.
Rozwiązanie do monitoringu oparte na AI oraz semantycznej analizie zależności
Wykrywanie anomalii jest pierwszą ważną cechą najnowszych platform monitorujących (Next Generation Monitoring). Kolejną, dużo bardziej istotną, jest automatyczna detekcja problemów. Ta wymaga rozumienia kontekstu transakcji oraz wykrywania wzajemnych powiązań pomiędzy komponentami (tzw. analiza semantyki). Według raportu „The Forrester Wave: Application Performance Management” z 2016 r., połączenie obu cech pozwala na:
• Uzyskanie perspektywy end-to-end dla wydajności aplikacji dla wszystkich użytkowników systemu – klientów i pracowników. Problemy mające wpływ użytkowników rzadko są osadzone w jednej warstwie, np. bazie danych, serwerze sieciowym czy kodzie aplikacji.
• Osiągnięcie większej częstotliwości i jakości wydań aplikacji – metodyki DevOps daje możliwość realizacji wydań aplikacji w warunkach szybko zmieniających się potrzeb klientów.
• Poprawienie efektywności i redukcję kosztów wynikających z automatyzacji – wraz ze wzrostem złożoności technologicznej aplikacji, pojawia się konieczność inteligentnej automatyzacji i uczenia maszynowego, aby rozwiązywać problemy szybciej przy jednocześnie mniejszym nakładzie pracy.
• Zwiększenie roli i demonstrację wartości zespołów I&O – wśród zgiełku wskaźników technologicznych, alertów i alarmów, zespoły I&O poświęcają coraz większą uwagę perspektywie klienta końcowego i użytkownika biznesowego. Rozwiązania monitorujące muszą wprowadzać korelację zdarzeń i mechanizmy analityczne, które ułatwiają identyfikację przyczyn problemów – bieżących i potencjalnych. Tym samym zmienia się rola działów operacji – przejście od typowego „operatora biznesu” do roli „challengera”.
Tym, co wyznacza nowy trend w monitoringu, jest wbudowany w platformę Dynatrace tzw. mechanizm analizy i wizualizacji postępowania problemu (Problem Evolution) – unikalna funkcjonalność pozwalająca na identyfikację źródła problemu oraz obrazująca jego wpływ na ekosystem aplikacji.
Raport ten potwierdza, że na obecnym poziomie złożoności systemów wymagana jest automatyzacja procesu identyfikacji problemów, a ta bez wsparcia sztucznej inteligencji (AI) oraz uczenia maszynowego (ML) nie ma szans powodzenia. Na tym tle warto zwrócić uwagę na ostatnie osiągnięcia firmy Dynatrace uznanej przez Forrester Research za lidera w obszarze monitoringu – zarówno pod kątem wizji, jak i kompletności portfela.
Dynatrace, jako pierwszy dostawca, wprowadza na rynek rozwiązanie do monitoringu, które na podstawie sztucznej inteligencji oraz semantycznej analizy zależności dokonuje automatycznej identyfikacji problemów. To, co Uber częściowo osiągnął w projekcie Argos w zakresie detekcji anomalii, Dynatrace wprowadził jako powszechnie dostępną technologię już w roku 2014. Najnowsza wersja platformy Dynatrace wprowadza istotne innowacje. Wśród nich warto wskazać:
• Smartscape – pozwala na automatyczne wykrywanie topologii aplikacji i jej stosu technologicznego, w tym Cloud Foundry, OpenShift, Docker, Mesos, DC/OS, Open- Stack, Oracle Cloud, AWS, Azure).
• Wykrywanie ponad miliarda zależności – które nie muszą mieć trwałego charakteru, dla stron www, usług, procesów, hostów, sieci oraz infrastruktury funkcjonującej w chmurze.
• Automatyczne uczenie się zachowania systemu w normalnych warunkach – a następnie identyfikowanie anomalii na podstawie sztucznej inteligencji, bez potrzeby definiowania progów alertowych dla metryk.
• Algorytmy sztucznej inteligencji dodatkowo określają, czy problem ma wpływ na rzeczywistych użytkowników systemu.
Nowy trend w monitoringu
Tym, co wyznacza nowy trend w monitoringu, jest wbudowany w platformę Dynatrace tzw. mechanizm analizy i wizualizacji postępowania problemu (Problem Evolution) – unikalna funkcjonalność pozwalająca na identyfikację źródła problemu oraz obrazująca jego wpływ na ekosystem aplikacji. Warto dodać, że w tle działa Purepath – znana i opatentowana przez Dynatrace technologia, która, analizując wydajność aplikacji, pozwala na automatyczną identyfikację wąskich gardeł, dotyczących problemu synchronizacji (kod aplikacji wykonywany w bloku synchronicznym), n+ 1 queries (problem nieefektywnej komunikacji, wynikający z błędnej konfiguracji O/RM), wielowątkowości czy np. komunikacji i realizacji asynchronizmu.
Inteligencja zaszyta w Next Generation Monitoring jest w stanie wygenerować alert z informacją o zagrożeniu dla usług biznesowych, tylko jeśli zaburzenia w działaniu poszczególnych elementów środowiska są widoczne dla użytkowników końcowych. W dobie cyfryzacji, przy konieczności przetwarzania niespotykanej dotąd ilości danych, Diagnostics Intelligence – i związane z tym procesy automatyzacji – mogą ułatwić proces nadzoru nad bieżącym działaniem złożonych systemów oraz dostarczyć I&O argumenty do zbudowania przewagi rynkowej nad konkurencją. AI i analiza semantyki są kluczem do osiągnięcia celu.