

RozwiązaniaAplikacjeInfrastrukturaPREZENTACJA PARTNERA
Jak ocenić wydajność sieci IT z punktu widzenia jej użytkowników i dlaczego warto to robić?
Advertorial
W świecie, w którym coraz większa liczba krytycznych aplikacji jest przenoszona do publicznej chmury obliczeniowej, potrzebne stają się nowe wskaźniki, pozwalające lepiej priorytetyzować działania, które mają na celu zapewnienie jak najlepszej efektywności środowisk IT. Podstawą do decyzji w tym obszarze powinna być wydajność aplikacji widoczna z perspektywy ich użytkowników.

W miarę jak środowiska aplikacyjne ewoluują w kierunku podejścia hybrydowego oraz w ślad za postępującą ewolucją modelu zakładającego wykorzystanie oprogramowania w formie usługi, coraz większym wyzwaniem staje się szybkie eliminowanie nieprawidłowości w działaniu infrastruktury, a nawet zapewnienie bieżącego wglądu w działanie wszystkich warstw nowoczesnej infrastruktury IT.
Konieczne mierzenie doświadczeń użytkowników aplikacji krytycznych
Jednocześnie, wobec rosnącej skali wykorzystania modelu publicznej chmury obliczeniowej do rangi zagadnienia krytycznego urasta ustanowienie odpowiedniego poziomu obserwowalności warstwy sieciowej. Równolegle zaś, powszechne przejścia do modelu pracy hybrydowej stanowią utrudnienie dla operacji zmierzających do określenia zakresu oraz pierwotnych przyczyn ewentualnych problemów z wydajnością. Wszystko to w realiach wyzwań operacyjnych, z którymi muszą radzić sobie – przeciążone – zespoły utrzymania.
Niezbędne staje się więc zastosowanie dodatkowej miary pozwalającej na szybkie i trafne określenie, które nieprawidłowości w działaniu infrastruktury sieciowej w największym stopniu przekładają się na możliwość realizacji celów biznesowych organizacji. Miarą taką są doświadczenia osób korzystających z poszczególnych, najczęściej krytycznych, aplikacji.
W przypadku użytkowników wewnętrznych zapewniają one perspektywę łączącą kwestie dotykające wydajności sieci i aplikacji, a więc także efektywności pracy. W kontekście użytkowników zewnętrznych – klientów – miara ta pozwala m.in. ocenić ryzyko utraty danego klienta lub szanse na wzmocnienie działań sprzedażowych.
W przypadku dzisiejszych – szybkich, hybrydowych sieci chmurowych – niezbędne stają się rozwiązania pozwalające automatyzować przepływy pracy oraz podstawowe działania administracyjne, ponieważ umożliwiają one wydatne skrócenie czasu reakcji całego zespołu.
Biznesowa metryka efektywności IT
Z punktu widzenia zespołów IT wykorzystanie kwestii zadowolenia użytkownika końcowego w roli ostatecznego wskaźnika kondycji sieci otwiera możliwość proaktywnego zarządzania jakością usług IT. Jest także sposobem na ograniczenie tzw. luki widoczności zjawisk zachodzących w warstwie sieciowej.
Problem jest o tyle poważny, że – jak pokazują analizy Enterprise Management Associates (EMA) – aż 40% problemów z wydajnością jest najpierw wykrywanych przez użytkowników końcowych oraz klientów. Jednocześnie, nawet 80% problemów dotykających użytkowników końcowych nie jest nigdy zgłaszanych zespołom utrzymania. Użytkownicy zdecydowanie częściej ignorują błędy lub znajdują sposób na ich ominięcie (użytkownicy wewnętrzni) lub porzucają transakcję (klienci).
Na tym nie koniec. Z analiz Forrester Research wynika, że rozpatrzenie aż 33% skarg użytkowników trwa dłużej niż miesiąc lub nie następuje nigdy! Natomiast rozwiązanie aż 31% zgłaszanych przez użytkowników problemów z wydajnością sieci zajmuje więcej niż miesiąc. Statystyki te wprost pokazują, jak duże znaczenie dla możliwości realizacji celów biznesowych ma sprawne działanie infrastruktury sieciowej oraz – co nie mniej istotne – zdolność organizacji do szybkiego identyfikowania i usuwania problemów występujących w tej warstwie.
Wynika to wprost z faktu, że w czasach, kiedy obsługa procesów w firmie wymaga wykorzystania wielu aplikacji, zapewnienie nieprzerwanego dostępu do nich jest krytyczną potrzebą biznesową. Podobnie zresztą jak zapewnienie wysokiej dostępności ich samych. Brak możliwości skutecznego wykonania przez pracowników rutynowych zadań – takich jak fakturowanie, obsługa klienta czy sterowanie produkcją – przekłada się na realne ryzyko strat, przestojów i utraconych wpływów.
Zespoły IT pod coraz większą presją
Na wymagania związane z koniecznością zapewnienia sprawnego i nieprzerwanego działania środowisk aplikacyjnych nakłada się także rosnąca złożoność infrastruktury IT. Stopień skomplikowania zależności pomiędzy poszczególnymi elementami środowisk aplikacyjnych rośnie m.in. na skutek postępów cyfrowej transformacji, wdrażania kolejnych usług IT, w tym zasobów chmurowych. Trendy w kierunku migracji do chmury i pracy zdalnej nadal zaciemniają widoczność wszystkich zdarzeń zachodzących w sieci, ich skutków oraz współzależności. W efekcie, rozwiązywanie problemów pojawiających się w obszarze IT staje się coraz bardziej złożone.
Z drugiej strony, w zespołach IT narasta problem przeciążenia pracą. Zjawisko to w szczególnym stopniu dotyka zespołów wsparcia pierwszej linii, nierzadko przytłoczonych zgłoszeniami, dla których nie ma jasno określonej ścieżki rozwiązania. Coraz bardziej powszechne stają się też luki kompetencyjne widoczne zwłaszcza wtedy, gdy złożoność sieci wykracza poza umiejętności mniej doświadczonych specjalistów IT.
Dlatego technicy i inżynierowie ds. sieci muszą poświęcać znaczne ilości czasu na zidentyfikowanie faktycznych źródeł problemów. Niezbędne staje się zatem nowe podejście i zestaw narzędzi pozwalających na skuteczne wykrywanie problemów, ocenę ich przyczyn oraz ich eliminowanie. Tymczasem, choć środowiska sieciowe przedsiębiorstw szybko się zmieniają, to zespoły wsparcia IT najczęściej wciąż korzystają z bardzo klasycznych metryk do monitorowania wydajności sieci oraz jakości świadczonych usług.
W jaki jednak sposób zespoły IT, polegające na tradycyjnych wskaźnikach wydajności, mają uzyskać wgląd w doświadczenia użytkowników korzystających z usług świadczonych za pośrednictwem nowoczesnych, hybrydowych środowisk? Nie jest to możliwe.
Rozwiązania VIAVI Solutions mogą przetwarzać zróżnicowane dane z wielu źródeł. Ułatwiają też skuteczne wykrywanie oraz izolowanie problemów w warstwie sieci, aplikacji, serwera, a nawet domeny klienta. Samą zaś interpretację danych ułatwiają kokpity menedżerskie dostosowane do roli użytkowników.
Nowe narzędzie do skutecznej diagnostyki sieci
Skuteczna strategia zarządzania siecią nie polega dziś na posiadaniu większej ilości danych dotyczących wydajności, ale na posiadaniu odpowiednich danych, które pozwolą określić pierwotną przyczynę problemu. W przypadku dzisiejszych – szybkich, hybrydowych sieci chmurowych – zespoły wsparcia IT potrzebują łatwego dostępu do wiedzy zapisanej w szczegółowych danych pakietowych, danych na temat ruchu sieciowego oraz informacji o użytkownikach. Niezbędne stają się też rozwiązania pozwalające automatyzować przepływy pracy oraz podstawowe działania administracyjne, ponieważ umożliwiają one wydatne skrócenie czasu reakcji całego zespołu.
W kontekście powyższych potrzeb nie dziwi, że rynek oprogramowania wspierającego monitoring oraz diagnostykę działania sieci rozwija się dynamicznie. Do ścisłej czołówki światowego rynku tego typu narzędzi należą – oferowane w Polsce przez Omnilogy – rozwiązania firmy VIAVI Solutions. Działając w sposób zintegrowany, zapewniają one m.in. kompleksowy monitoring wydajności i poziomu bezpieczeństwa sieci oraz rozbudowane funkcje raportowania, w tym możliwość wglądu w otrzymane wyniki z zachowaniem pełnego kontekstu oraz informacji na temat współzależności.
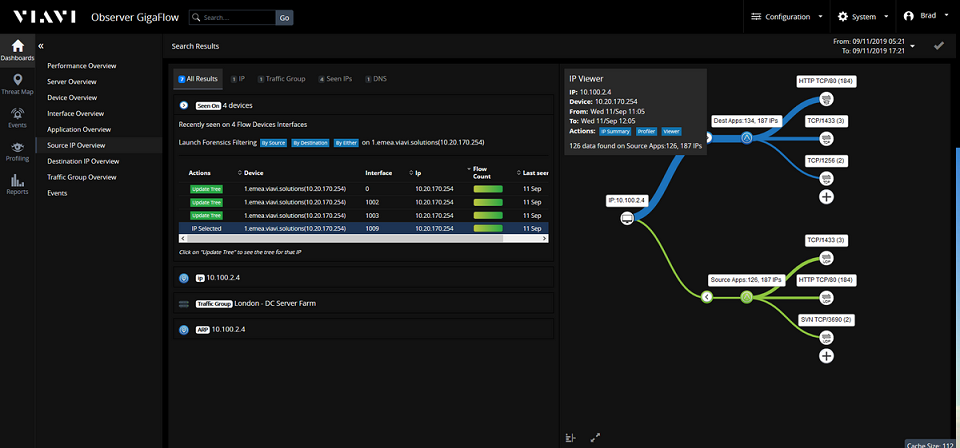
Co więcej, rozwiązania VIAVI Solutions w unikalny sposób łączą funkcjonalność z zakresu monitoringu oraz diagnostyki sieci z mechanizmami scoringu doświadczeń użytkowników końcowych. Na potrzeby monitorowania oraz oceny ich doświadczeń – a także zapewnienia w czasie rzeczywistym wglądu w złożone informacje i za pomocą jednego, intuicyjnego wskaźnika – rozwiązania VIAVI wykorzystują m.in. złożone algorytmy uczenia maszynowego.
W celu uzyskania uproszczonej, ale przejrzystej i miarodajnej oceny jakości usług rozwiązania VIAVI Solutions mogą przetwarzać zróżnicowane dane z wielu źródeł. Równocześnie, rozwiązania te ułatwiają skuteczne wykrywanie oraz izolowanie problemów w warstwie sieci, aplikacji, serwera, a nawet domeny klienta. Samą zaś interpretację danych na temat wydajności całej sieci ułatwiają intuicyjne i łatwo dostępne wizualizacje i wskaźniki prezentowane w ramach kokpitów menedżerskich dostosowanych do roli użytkowników. Wszystko po to, aby umożliwić bardziej proaktywne i wydajne wsparcie IT.
Oferta rozwiązań VIAVI do analizy ruchu sieciowego w kontekście doświadczeń użytkowników końcowych:
- VIAVI Observer – kompleksowe rozwiązanie do monitorowania wydajności sieci i analizy bezpieczeństwa.
- Observer Apex – dostarcza funkcjonalności pozwalające na wielowymiarową ocenę doświadczeń indywidualnych użytkowników końcowych dla każdej transakcji.
- Observer GigaStor – urządzenie do przechwytywania i analizy pakietów danych przesyłanych za pośrednictwem monitorowanej infrastruktury sieciowej.
- Observer GigaFlow – zapewnia mechanizmy analizy rekordów NetFlow, integrując wiele źródeł danych o ruchu i sieci, a także głęboki wgląd w bezpieczeństwo infrastruktury.
Monitoring doświadczeń według VIAVI
Ocena kondycji sieci poprzez przeglądanie niekończących się list wskaźników KPI – bez wyraźnego celu ani kierunku – staje się niewykonalna. Miarą prowadzącą do efektywnej priorytetyzacji i ważenia metryk jakości działania sieci powinno być zatem zadowolenie użytkowników końcowych.
Monitorowanie doświadczeń użytkowników końcowych EUE (End User Experience) zapewnia dodatkowy kontekst niezbędny do efektywnego mierzenia oraz priorytetyzacji danych sieciowych, a co za tym idzie – lepszą widoczność oraz dodatkową analizę wskaźników wydajności pod kątem proaktywnego wykrywania potencjalnych problemów. EUE oparte są na:
- Ocenie doświadczeń użytkowników końcowych – służącej do ilościowego określenia wydajności w skali numerycznej i ustalenia progów działania. Wyniki zbiorcze odzwierciedlają, przykładowo, wydajność witryny lub aplikacji, podczas gdy poszczególne wyniki EUE charakteryzują doświadczenia pojedynczych użytkowników.
- Opatentowanym przez VIAVI scoringu EUE – składa się na niego ocena 30 kluczowych wskaźników wydajności (KPI) zinterpretowanych za pomocą platformy Observer Apex do postaci prostych, oznaczonych kolorami wyników.
- Kokpitach menedżerskich – zapewniających łatwy dostęp do wniosków z przeprowadzonych analiz. Zawierają one intuicyjne listy witryn oraz aplikacji, dla których dostępne są dane EUE. Możliwość drążenia danych dostępnych w ramach kokpitów pozwala odkryć interakcje i zależności wskazujące na pierwotne przyczyny niskich wyników EUE.
Co ważne, ilość i różnorodność danych dostępnych obecnie dla zespołów IT przekładają się na możliwość prowadzenia bardziej złożonych analiz, wyższy poziom widoczności zdarzeń zachodzących w środowisku IT oraz dostęp do detalicznych danych na ich temat.
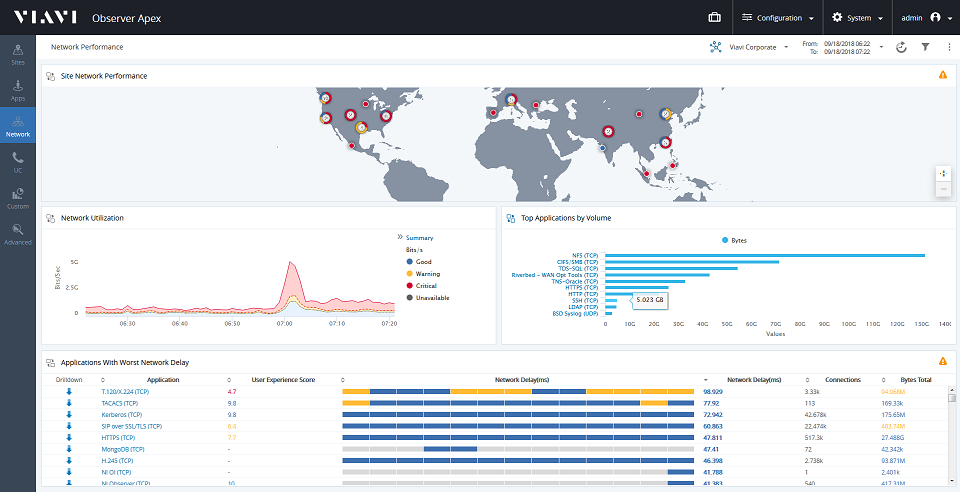
Metryki istotne w kontekście monitorowania doświadczeń użytkowników końcowych
Oprogramowanie VIAVI – zbierając i korelując w sposób inteligentny wskaźniki najbardziej krytyczne z perspektywy użytkownika końcowego – dostarcza praktycznych danych w intuicyjnej formie. Analizie poddawane są zarówno dane techniczne, dotyczące przepływu danych oraz przesyłanych pakietów danych, jak i informacje dotyczące wydajności powiązanych usług w szerokim spektrum przypadków użycia.
Kluczowe źródła takich wskaźników to:
- Rekordy przepływu (Flow Records) – przechwytują istotne informacje o interfejsach i innych elementach konwersacji sieciowej, w tym adresy IP oraz dane protokołów, znaczniki czasu i identyfikatory urządzeń, aby uzyskać jak najbardziej szczegółowe informacje na temat ruchu i trendów użytkowania usług sieciowych. Rekordy przepływu VIAVI Enriched-Flows integrują pochodzące z wielu źródeł dane przepływów w celu zapewnienia kontekstu między użytkownikiem, adresem IP, adresem MAC i wykorzystaniem aplikacji.
- Dane pakietowe (Packet Data) – zawierają ważne identyfikatory użytkownika, urządzenia i źródła, a także szczegółowe informacje o przeglądarce i aplikacji bezpośrednio na podstawie analizy pakietów sieciowych. Na bazie tego typu danych można mierzyć wskaźniki wydajności, takie jak jitter, a także statystyki strat i retransmisji. Wiodące możliwości przechwytywania, przechowywania oraz analizy danych pakietowych zapewnia urządzenie VIAVI GigaStor.
- Aktywny monitoring (Active Monitoring) – zapewnia funkcjonalność strategicznego monitorowania wydajności stron trzecich w oparciu o zautomatyzowane skrypty testowe oraz mechanizmy symulujące zachowania użytkowników. Ruch syntetyczny można dostosować tak, aby obejmował szeroki zakres przypadków użycia i warunków, co przekłada się na szerokie spektrum możliwości monitorowania aplikacji z perspektywy użytkowników końcowych.
Nowoczesny monitoring sieci w praktyce
Rosnąca złożoność środowisk aplikacyjnych, mnogość modeli ich użycia oraz konieczność zagwarantowania użytkownikom łatwego, nieprzerwanego i nieograniczonego funkcjonalnie dostępu do aplikacji biznesowych z dowolnego miejsca oznaczają, że tradycyjne granice firmowych sieci IT przestają istnieć. Nie oznacza to jednak, że znaczenie infrastruktury sieciowej maleje. Jest dokładnie odwrotnie.
Dostępność aplikacji lub ergonomia ich użycia mogą szybko ulec pogorszeniu, jeśli jakikolwiek element sieci – lub architektury usług – ulegnie awarii. W świecie powszechnej digitalizacji kontaktów z nabywcami oraz rosnącej złożoności i dynamiki procesów biznesowych, każdy spadek jakości usług IT może zaś przekładać się na słabą satysfakcję klientów i zmniejszoną rentowność biznesu. Koniecznością staje się więc zapewnienie wszechstronnej obserwowalności w zakresie całej infrastruktury oraz kontekstu użytkowego niezbędnego do podejmowania racjonalnych decyzji, mających na celu neutralizowanie skutków ewentualnych awarii.
Observer Apex to pierwsze rozwiązanie do monitorowania wydajności sieci, które zapewnia ocenę doświadczeń użytkownika końcowego dla każdej transakcji. Możliwości pozyskiwania danych z wielu zróżnicowanych źródeł sprawiają, że rozwiązanie to gwarantuje całościowy wgląd w aktualny stan usług IT oraz ich wpływ na przebieg procesów biznesowych. Dzięki temu – w przypadku wystąpienia jakiejkolwiek anomalii w działaniu poszczególnych usług IT lub w razie wykrycia naruszenia bezpieczeństwa – zespoły NetOps, DevOps i SecOps mogą zidentyfikować i usunąć pierwotne przyczyny problemów, a nie tylko ich skutki.
Marcin Gryczon, Sales Manager, Omnilogy
Omnilogy jest przedstawicielem VIAVI Solutions w Polsce.





