

AplikacjeRynekPolecane tematy
Polscy naukowcy opracowali duży model językowy bardziej wydajny niż ChatGPT
Mowa o LongLLaMa, który oparto na oprogramowaniu OpenLLaMA, stworzonym przez Meta – właściciela Facebooka. Ten duży model językowy opracowany przez naukowców z UW, PAN i IDEAS NCBR ma pozwolić obsługiwać 64 razy więcej tekstu niż ChatGPT. To osiągnięcie zapowiada nowy krok w rozwoju modeli językowych. Opublikowane wyniki polskich uczonych odbiły się głośnym echem w środowisku badaczy IT. Publikację na ten temat przyjęto na prestiżową konferencję naukową NeurIPS 2023.
LongLLaMA opracowali Szymon Tworkowski, Konrad Staniszewski, Mikołaj Pacek i Piotr Miłoś, badacze związani z IDEAS NCBR, Uniwersytetem Warszawskim i Polską Akademią Nauk, oraz Yuhuai Wu, jeden ze współtwórców xAI, startupu Elona Muska, a także Henryk Michalewski, związany z UW i Google DeepMind. Badacze, publikując w ostatnich tygodniach swoje wyniki, wzbudzili poruszenie w społeczności naukowej. Publikacja poświęcona LongLLaMA – „Focused Transformer: Contrastive Training for Context Scaling” – została przyjęta na prestiżową konferencję NeurIPS 2023 w Nowym Orleanie.
„LongLLaMA to polski duży model językowy, dostępny dla każdego w internecie” – mówi dr hab. Piotr Miłoś, prof. Polskiej Akademii Nauk, lider zespołu badawczego w IDEAS NCBR, który przyczynił się do opracowania modelu. „Nasz model może obsługiwać jednorazowo 8 tysięcy tokenów, czyli w przybliżeniu 30-50 stron tekstu, a w przypadku niektórych zadań znacznie więcej, nawet 256 tysięcy tokenów, chociaż to tylko wynik techniczny” – dodaje.
Jak się okazuje, od marca br. zaczęły pojawiać się pierwsze duże otwarte modele językowe o otwartym kodzie źródłowym. Pozwalają one naukowcom na zaawansowane prace, bo obecnie nie można stworzyć własnego LLM od zera. Kiedy Meta, właściciel Facebooka, wypuściła OpenLLaMA, naukowcy z całego świata – między innymi polski zespół – wzięli go na warsztat i modyfikowali. „Nasza LongLLaMA jest w stanie przetwarzać znacznie większy kontekst niż było to wcześniej możliwe, czyli potrafi w jednym kawałku „zjeść” znacznie więcej tekstu” – tłumaczy dr hab. Piotr Miłoś.
Ogromne możliwości i niezwykła dokładność
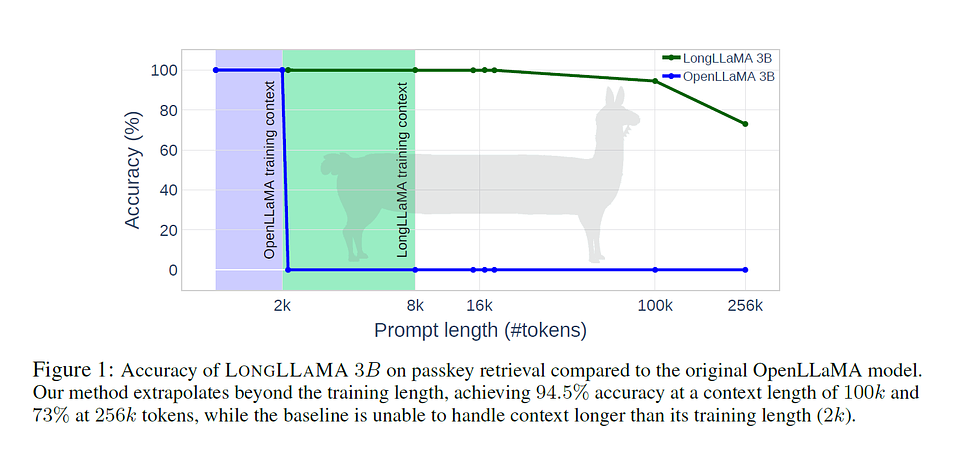
Przewaga LongLLaMA nad innymi modelami polega na tym, że potrafi przetwarzać bardzo długie dane wejściowe. Dzięki temu generuje bardziej spójne i trafne odpowiedzi. LongLLaMA może obsłużyć dowolną ilość kontekstu bez obcinania go i wypełniania, co pokazały testy z hasłem (passkey). Badacze sprawdzali, czy po otrzymaniu bardzo długiego promptu LongLLaMA będzie w stanie przypomnieć sobie hasło podane na początku. Podczas, gdy OpenLLaMA dawała sobie radę tylko z promptem o długości 2 tysięcy tokenów (w przypadku dłuższych kontekstów jej efektywność spadała do zera), LongLLaMA utrzymywała 94,5% dokładności po otrzymaniu promptu o długości 100 tysięcy tokenów i 73% dokładności po otrzymaniu 256 tysięcy tokenów.
Co więcej, model ten potrafi obecnie wytwarzać spójne teksty o długości 8 tysięcy tokenów, a potencjalnie nawet 256 tysięcy tokenów, w czym znacząco przewyższyłby m.in. ChatGPT. Co istotne, zużywa stosunkowo mało energii – do korzystania z LongLLaMA wystarczy pojedynczy procesor – i pracuje bardzo szybko. Może być wykorzystywana do wszystkich zadań, w których już pomagają nam chatboty. Chodzi np. o: generowanie tekstu, edycję tekstu, rozmowę z użytkownikiem, tworzenie streszczeń, tłumaczenie itd.
Jak wyobrazić sobie różnicę? Gdyby dla uproszczenia przyjąć, że 1 token to 1 słowo, podkreślmy, że 2 tysiące słów posiada mniej więcej 7-stronicowy artykuł. 256 tysięcy słów to w przybliżeniu długość powieści Harry Potter i Zakon Feniksa (257 tys. słów) albo Ulissesa (265 tys. słów).
Czym różni się LongLLaMA od ChatGPT?
LongLLaMA w przeciwieństwie do najsłynniejszego dotąd chatbota – ChatGPT nie posiada interfejsu w internecie, ale każdy może pobrać model ze strony HuggingFace i uruchomić go na własnym komputerze. Otwarte oprogramowanie mogą modyfikować informatycy na całym świecie, co odróżnia je od oprogramowania ChatGPT, które nie zostało udostępnione publicznie, choć wiadomo, że również bazuje na architekturze Transformer. Jest to rodzaj architektury sieci neuronowej, która analizuje tekst, aby rozróżnić skomplikowane powiązania między słowami na wielu warstwach, ucząc się wzorców na podstawie ogromnych ilości danych. Technologia ta zrewolucjonizowała przetwarzanie języka naturalnego, umożliwiając chatbotom generowanie tekstu, tłumaczenie, rozmawianie z użytkownikiem i wiele innych zadań na poziomie niedostępnym wcześniej dla sztucznej inteligencji.
Kiedy zadajemy pytanie chatbotowi korzystającemu z Transformera, zmienia on tekst na tokeny. Są to fragmenty informacji, zwykle mające długość pomiędzy jednym znakiem a jednym słowem. W zdaniu „W 2023 roku, niespodziewanie, chatboty zmieniły nasze życie” czatbot może zobaczyć przykładowo siedem słów, liczbę 2023, dwa przecinki i kropkę. Dzięki dzieleniu tekstu na tokeny sztuczna inteligencja potrafi efektywnie przetwarzać informacje.
Jednak liczba tokenów, jaką może przyjąć chatbot jest ograniczona – w przypadku ChatGPT 3.5 limit tokenów wynosi 4096, OpenLLaMA – 2000, a Google Bard – około 1000. Dlatego, gdy zadajemy chatbotowi długie pytanie lub podajemy dużo informacji, może być konieczne ucięcie lub pominięcie niektórych fragmentów, aby zmieścić się w limicie tokenów. Większość istniejących chatbotów nie potrafi analizować całej książki, długiej rozmowy czy artykułu.
„Pełny potencjał dużych modeli językowych jest często ograniczony ze względu na to, ile kontekstu może przyjąć dany model. Dlatego wprowadziliśmy Focused Transformer (FoT), technikę wykorzystującą proces szkoleniowy inspirowany uczeniem kontrastowym (contrastive learning). To nowatorskie podejście pozwala na strojenie (fine-tuning) dostępnych już LLM, tak by były zdolne przyjmować większy kontekst” – wyjaśnia Piotr Miłoś. „ChatGPT jest produktem komercyjnym. Został optymalizowany pod przyjemną obsługę. Modele takie jak LongLLaMA wydają raczej surowe informacje, na których dopiero można coś zbudować, np. analizować tekst albo produkować kod. LongLLaMA to duże osiągnięcie, ponieważ pokazuje, że duże modele językowe mogą pokonać ograniczenia związane z długością promptów i wytwarzać długie teksty, które będą przydatne dla człowieka” – podsumowuje badacz IDEAS NCBR i PAN.





