

Debata ITwizSztuczna inteligencjaCDOPolecane tematy
Czy zmierzamy w Polsce w stronę Data Driven Enterprise?
DEBATA ITWIZ
Kolejna debata ITwiz poświęcona była budowie modelu firmy opartej na danych. Jej uczestnicy – z takich firm, jak Centralny Ośrodek Informatyki, Empik Group, Hewlett Packard Enterprise, Reckitt i Tauron Obsługa Klienta – zastanawiali się, czy jesteśmy świadkami przełomu w tym obszarze w zastosowaniem w biznesie modeli LLM; omawiali własne doświadczenia i wyzwania w budowie świadomości, kompetencji, oraz relacji i współpracy z biznesem; a także dyskutowali jak zapewnić ład w zarządzaniu danymi.

W jakim punkcie drogi do Data Driven Enterprise znajdują się dziś Panów firmy?
Dariusz Gregorczyk, Head of BI & Data Solutions, Empik Group: Nasza podróż w tym kierunku jest równie unikalna, jak i pouczająca. Określiłbym nasze położenie na tej drodze jako niejednorodne. Nie deklarujemy, że jesteśmy – albo zmierzamy – w stronę Data Driven. I to, uważam, jest właściwe, ponieważ wiele firm składa takie deklaracje, ale pozostają one tylko deklaracją na papierze, a raczej w prezentacji Power Point.
Brak takiej deklaracji z naszej strony powoduje, że nie buduje się zamków na piasku, tylko organicznie kładzie fundamenty. Z jednej strony, nie głosząc wielkich haseł o Data Driven, szeroko otworzyliśmy się na demokratyzację danych. Jest to jedno z naszych kluczowych osiągnięć, z którego możemy być dumni, ale biznesowo buduje to przede wszystkim naszą przewagę konkurencyjną. Poprzez hurtownię danych, modele BI i Power BI na co dzień dostęp do danych posiada 700 osób, które przeprowadzają analizy i budują własne raporty. Liczba tych raportów przekroczyła właśnie 4200 i przyrasta niemal w postępie geometrycznym. To pokazuje jak głęboko jesteśmy zanurzeni w danych.
Z drugiej strony mimo sukcesów w tym obszarze, brakowało nam jednak spójności i zsynchronizowanego planowania. Przykładowo wiemy, że przy tej liczbie raportów część z nich musi się pokrywać, ale nie znamy skali tego zjawiska. Dziś silnie odczuwamy więc potrzebę przebudowy architektury danych, ustandaryzowania raportowania i stworzenia wspólnego słownika pojęć biznesowych. Mając świadomość ogromu pracy „do odrobienia” przystępujemy do niej etapami: staramy się wyłuskiwać mocniejsze pod względem kompetencji oraz doświadczenia obszary, by wspólnie z nimi przebudowywać infrastrukturę danych.
Dlatego powiedziałem, że nasze położenie jest niejednorodne. Nie zarządzaliśmy tym zagadnieniem w skali makro, więc nie zbudowaliśmy pełnej świadomości konsekwencji po stronie biznesu. A jednocześnie pewne rzeczy postępują bardzo szybko i dużo szerzej, niż w innych firmach.
Spróbuję więc określić nasze miejsce w tej marszrucie następująco: jest to bardzo ważny i trudny moment, ponieważ trzeba ostatecznie takie ramy nadać. Trudny, ponieważ wiele spraw zaszło już bardzo daleko, ale trzeba je uporządkować – zarówno jeśli chodzi o narzędzia, jak i hurtownię danych. Będzie to przypominało strzyżenie nieco zapuszczonego ogrodu, nadanie kształtów i form całości, po to, aby można było ocenić, gdzie realnie w podroży do Data Driven jesteśmy.
Leszek Chwalik, wiceprezes Tauron Obsługa Klienta: Świadczymy usługi dla wszystkich spółek Grupy, w których w zasadzie nie ma IT. Mamy świadomość, że od lat gromadzimy i przetwarzamy ogromną ilość danych, ale nie do końca efektywnie z nich korzystamy. Mamy też różną sytuację w obszarach biznesowych np. w obszarze sprzedaży energii i dystrybucji.
W tym pierwszym obszarze dominuje analityka przetwarzania transakcyjnego. Pojawiają się potrzeby badania zachowania klienta, jego preferencji, jego potrzeb, ponieważ rynek jest w tym obszarze otwarty. W tym kontekście stworzyliśmy jakiś czas temu wizję Data Governance na poziomie Grupy. Próba wprowadzenia takiego generalnego, nadrzędnego i na szeroką skalę modelu ostatecznie nie powiodła się.

Snop mocnego światła padł właśnie w sektorze retail na obszar danych. Rodzi to wielkie oczekiwania i nadzieje. Ale zwrócę uwagę na wymóg budowy świadomości. A świadomość to już jest inny proces, ponadbranżowy i ona się tak szybko nie zmienia – Dariusz Gregorczyk, Head of BI & Data Solutions, Empik Group.
Postanowiliśmy więc zamiast rewolucji dokonać zmian ewolucyjnych. Wykorzystując narzędzia, które miały służyć już w poprzednim modelu, potrzebę i chęci jednego z naszych klientów, rozpoczęliśmy projekt obejmujący opracowanie modelu danych, budowę kompetencji i następnie jego wdrożenie. Powstał schemat ról i zadań oraz odpowiedzialności, w którym nasz klient potrafi odpowiednio wykorzystać i docenić dostarczane przez nas surowe dane. Resztę pozostawiamy im a widać, że mają „frajdę” z tego co robią. W pozostałej części Grupy biznes jest świadomy, że posiada dane, ale próbuje wykorzystywać je na własnych zasadach, przy pomocy różnych narzędzi, np. Power BI.
Ma to duże znaczenie, ponieważ pozwala wspierać rozwój kompetencji analitycznych w biznesie, poznać moc danych. A to, czego nam brakuje lub są niewystarczające, to kompetencje, które stanowią fundament dalszego rozwoju. Wszystkich, którzy angażują się już na obecnym poziomie w pracę z danymi ciężko jest wyciągnąć do jednostki, która docelowo mogłaby stanowić wspólne centrum kompetencji i usług w tym zakresie. Moglibyśmy wówczas wykorzystać ogromny, drzemiący potencjał kompetencji i narzędzi oraz danych z różnych obszarów biznesowych.
Jako Grupa, jesteśmy właścicielem różnych danych z obszaru wytwarzania, sprzedaży, dystrybucji. Dodatkowo chcemy w dalszym ciągu pozyskiwać i agregować dane zewnętrzne, np. udostępniane przez samorządy i klientów. Skorelowane, dostarczyłyby przełomowych informacji dla nas i naszych klientów. Nie przesadzę, jeśli powiem, że pozwoliłyby osiągnąć nam nowy poziom zarządzania i kreowania biznesu, predykcji. To przed nami.
Dzisiaj nie ma przestrzeni na to, aby rozpędzić się za mocno, ponieważ mamy szereg zmian prawnych, które trzeba uważnie wdrażać. To jest wyzwanie, ale i czysty zysk, ponieważ zmiany te porządkują sytuację np. Centralny System Informacji Rynku Energii, rynek mocy… Bez tego uporządkowania nie ruszymy dalej. Systemy transakcyjne nie były przygotowane na wymuszanie wprowadzania danych według określonych standardów, na ich walidację. Dlatego dzisiaj głównym nurtem jest uspójnienie, porządkowanie danych które są potrzebne. Kolejna runda to budowa modeli. Małymi krokami już to zaczynamy.
Planujemy budowę centrum kompetencji cyfrowych dla IT i OT oraz biznesu, który może się wyszkolić albo skorzystać z naszych usług. Chcemy też zainwestować w społeczność klientów, których jest 6 mln. Czerpać wartość od nich, informację, co by im pomogło, a może także przyszłych pracowników. Są zatem trzy nurty budowy kompetencji, zaczynając od siebie.
Artur Studziński, konsultant techniczny Hewlett Packard Enterprise: Nasza firma od dłuższego czasu przygotowywała się do momentu, który z całą siłą objawił się niedawno na rynku, do ery, w której do zsynchronizowanej, skorelowanej pracy użyte będą wszystkie dane powstające w procesach produkcji, sprzedaży, w toku całej działalności organizacji, a także w jej otoczeniu.
Demokratyzacja danych w dobie modeli językowych typu ChatGPT sprawi, że próg wejścia do tego, aby stać się kompetentnym pracownikiem organizacji zarządzanej w oparciu o dane, bardzo się obniżył. Wystarczy umiejętność zadania pytania w języku naturalnym, a model wydobędzie – z odpowiedniej bazy – odpowiedź w oparciu o informacje biznesowe.

Testem dla jakości i dojrzałości zarządzania danymi dla firm energetycznych jest wymóg gromadzenia danych na potrzeby Centralnego Systemu Informacji Rynku Energii. Unormowanie ich jakości w tym zbiorze otworzy operatorom możliwość rozwinięcia kolejnych usług – Leszek Chwalik, wiceprezes Tauron Obsługa Klienta.
Świat zarządzania danymi, który współtworzymy, obejmuje całe środowisko narzędzi o różnych zadaniach, także związanych z zarządzaniem poszczególnymi kategoriami narzędzi czy grupami modeli. Jest to niezbędne, ponieważ trudno sobie z jednej strony wyobrazić oparcie organizacji na jednym modelu, ale także na niezmiennych, nieadaptujących się nieustannie do rzeczywistości modelach. Muszą się uzupełniać i stale doskonalić.
To wymaga ram, własnych narzędzi, procesu. Badanie efektywności całościowo i w rozbiciu na poszczególne modele już jest ważne, a będzie kluczowe w przyszłości.
Piotr Hołownia, IT & Digital Director, Global Tech Platforms – Marketing & eRB (eCommerce), Reckitt: Patrzę z punktu widzenia globalnej organizacji i obecności na wielu rynkach, ale także wcześniejszych doświadczeń z budową produktów opartych o dane. Uważam, że kluczowe znaczenie mają odpowiednie kompetencje i świadomość w biznesie, celu i możliwości wykorzystania dostępnych danych.
Obecnie pracujemy w Reckitt przy budowie Data Ingestion Flow – strumienia przyswajania danych z systemów źródłowych do miejsca ich docelowego przetwarzania. Używamy do tego narzędzi i rozwiązań analitycznych na platformie Google Cloud Platform. Technologicznie budowa tych magazynów danych nie jest wyzwaniem, poza zagadnieniami typowymi dla integracji różnych środowisk i systemów Możemy już elastycznie konfigurować strumienie danych, w dowolnie zdefiniowanych konfiguracjach źródło-miejsce przetworzenia.
Kluczowe pytanie brzmi czy koleżanki i koledzy z biznesu będą w stanie wykorzystać te nowe możliwości i strumienie informacji, podnosić poziom wykorzystania, biegłości i intensywności operowania na danych. Z mojego punktu widzenia najważniejsza jest umiejętność formułowania zapytań i wyciągania wniosków. Do tego dążymy. Trzeba zatem pracować w organizacji nad rozwojem kompetencji. Szczególne znaczenie ma rola Data Steward’ów panujących nad modelami danych, wypracowujących obserwacje i serwujących dane.
Pokrewne zagadnienie to współpraca z partnerem w biznesie. Staramy się budować interakcję, dyskusję. Nie narzucamy sposobu wykorzystywania danych, bardziej naprowadzamy. Staramy się od samego początku identyfikować problem biznesowy i wspólnie wypracowywać odpowiedzi na pytania: „jak?” i „do czego?” wykorzystywać narzędzia. Odpowiedzi na te pytania pozostaną aktualne nawet kiedy zapanują modele oparte na języku naturalnym. Dlatego, że niezmiennie trzeba pytać, jaką wartość biznesową chcemy wyciągnąć z danych.
Krzysztof Chibowski, Advisory and Professional Services, Hewlett Packard Enterprise: W ostatnich latach HPE kompletuje środowisko do zarządzania danymi. Jest to reakcja na sytuację na rynku, m.in. na efekty strategii Cloud First. Takie podejście przyniosło rozczarowanie szeregowi firm przenoszących hurtem wszystkie rozwiązania on-premise do chmury obliczeniowej. W kontekście wykorzystania danych przez te rozwiązania, a także dostępu do nich i budowania na nich decyzji. Komunikacja z chmurą publiczną pogrążyła finansowo wiele z nich. W ostatnich 2 latach zaczęły się powroty do środowisk prywatnych, w których intensywne operowanie na danych nie wiąże się z ryzykiem finansowym.
Przeciwstawiłbym więc ten pierwszy buzzword, innemu, który robi karierę, czyli Data Gravity. Kiedy budujemy system, w którym mamy dane, to zaczyna on przyciągać dane z innych, mniejszych podzbiorów. Nikt nie pyta, czy to on-premise czy cloud, tylko: gdzie przyjęło się dane gromadzić.

Nasza firma od dłuższego czasu przygotowywała się do ery, w której do zsynchronizowanej, skorelowanej pracy użyte będą wszystkie dane powstające w procesach produkcji, sprzedaży, w toku całej działalności organizacji, a także w jej otoczeniu – Artur Studziński, konsultant techniczny Hewlett Packard Enterprise.
Obecnie wskazówka przesunęła się w stronę Data First lub Data Driven. To oznacza, że firmy, które wykonały wcześniej pracę nad uporządkowaniem danych, zyskały przewagę. Nie da się bez tych początkowych nakładów pracy przejść do AI i dużych modeli językowych, o których wspominał Artur. Jest to udziałem niewielkiej grupy organizacji, ponieważ według naszego badania zdecydowana większość klientów jest na poziomie 3 w 5-stopniowej skali (Data Anarchy – 10%, Data Reporting – 29%, Data Insights – 45%, Data Centricity – 15%, Data Economy – 1% – przyp. red.), jeśli chodzi o ich dojrzałość w kwestii wydobywania wartości z generowanych danych. Wciąż wykorzystują dane głównie na poziomie raportowym. Na poziomie 5 funkcjonuje zaś pełna monetyzacja danych.
Firmy średnio pracują na ok. 20% dostępnych danych, czyli tych ustrukturyzowanych. Reszta to dane nieustrukturyzowane. Połączenie uporządkowanego podejścia Data Driven, zastosowanie go do całości gromadzonych danych, pozwoli wykorzystywać możliwości w pełni. To przed nami.
Trzeba zastanawiać się nad demokratyzacją, ale także inwentaryzacją i oceną zasobu, jakim są dane. Niewiele firm to robi, najczęściej przeszkodą są istniejące silosy, nie wspominając o danych ze świata OT. Warto ocenić na ile są nadal potrzebne. Ostrożniej trzeba też podchodzić do danych OT. Nie powinno się ich udostępniać czy przenosić do chmury.
HPE od kilku lat dokonuje przejęć firm zorientowanych na dane, zarówno tworzących oprogramowanie, jak i hardware. Powstało portfolio dla klientów od strony analitycznej i AI, aby zbudować pełną ofertę as-a-service, ale w środowisku on-premise. W Polsce – według statystyk – ok. 18% firmowych systemów jest w chmurze. Zapewne współczynnik ten osiągnie niebawem poziom 20-25%. Ale trend adaptacji chmury publicznej wyhamowuje. Wynika to w oczywisty sposób z oszacowania wartości, jaką ta zmiana przynosi. Ocena nie wypada dobrze, dlatego firmy są bardzo konserwatywne i ostrożne.
HPE prowadzi rozmowy z klientami przez pryzmat wyzwań, które przed nimi stoją. W dużej mierze dotyczy to twardych umiejętności związanych z chmurą, która jest nieodłącznym – co nie oznacza wyłącznym – elementem architektury. Jest punktem odniesienia. Trzeba znać i dyskutować kwestie optymalizacji chmury, rozwoju usług w tych środowiskach, a także uwzględniać ten kontekst, kiedy chcemy rozmawiać o nadrzędnym celu: jak powinna wyglądać analityka w firmie? Po co to robić? Jakie przyjąć podejście do danych?
Tomasz Rychter, dyrektor Pionu Innowacji i Jakości, Centralny Ośrodek Informatyki: W COI nosimy wiele czapek, z jednej strony jesteśmy dostawcą oprogramowania dla Ministerstwa Cyfryzacji. Z drugiej działamy jako doradca, który podpowiada, jak działać. Jednocześnie w organizacji jest 1600 osób i mamy wewnętrzne wyzwanie posługiwania się danymi.
Centralny Ośrodek Informatyki zaczął od utrzymywania centralnych rejestrów państwowych – PESEL i CEPiK. Historycznie dane z tych systemów nie były podzielone na dane ogólnej natury dostępne szerzej i szczegółowe, które mogą służyć np. analityce. Aby myśleć o Data Driven robimy remanent danych w organizacji. Dookoła danych zaczęliśmy budować zespół i kompetencje. Jest to konieczne do efektywnego wypełniania roli doradcy dla Ministerstwa Cyfryzacji. Dane mają też służyć poszczególnym jednostkom – resortom i urzędom.

Pracujemy w Reckitt przy budowie Data Ingestion Flow – strumienia przyswajania danych z systemów źródłowych do miejsca ich docelowego przetwarzania. Używamy do tego narzędzi i rozwiązań analitycznych na platformie Google Cloud Platform – Piotr Hołownia, IT & Digital Director, Global Tech Platforms – Marketing & eRB, Reckitt.
Rozpoczęliśmy np. projekt System Dokumentacji Prawnej realizowany przy wsparciu Prokuratorii Generalnej RP do analizy dokumentów. Chcemy uspójnić wydawane opinie oraz przyspieszyć analizę, podejmowanie decyzji i wesprzeć tę organizację w tworzeniu pism. Jest to projekt innowacyjny, potrzebny, powstający z wykorzystaniem Machine Learning.
Mamy też dylemat, który jak sądzę będzie dotyczył także innych firm. Chodzi mianowicie o współdzielenie danych. Nasz przypadek dotyczy danych o energetyce, które gromadzą różne firmy tego sektora. Niezbędne jest udostępnianie i połączenia ich z myślą o bezpieczeństwie w skali państwa. Kto będzie prowadził Data Governance i zapewni, aby synergia danych posłużyła wszystkim? To przykład jednej branży, ale przecież projektuje się wymianę danych pomiędzy różnymi sektorami. Ich połączenie, zderzenie, obiecuje wielowymiarowe korzyści.
Sądzę, że ważną, ale otwartą kwestią jest przyznanie prymatu IT albo biznesowi w określaniu celów i środków transformacji ku Data Driven. Jestem przekonany, że kryterium powinna być ocena dojrzałości. Dobry konsulting powinien podpowiadać klientowi biznesowemu to, czego on nie wie. Spodziewam się, że kompetencje konsultingowe w IT będą szczególnie cenne przy budowie tego typu podejścia. Po drugiej stronie musi wówczas występować świadomość własnej niewiedzy.
Piotr Hołownia: Chciałbym zapytać trochę prowokacyjnie: na kim wówczas spoczywa odpowiedzialność? Dopóki firma jest na 2. poziomie dojrzałości, każdy – we własnym zakresie – korzysta z danych. Technologia oczywiście pomaga, biznes trochę korzysta, najczęściej przy pomocy narzędzi takich jak np. Power BI, z wizualizacji i raportów w określonym obszarze organizacji czy streamie biznesowym.
Gdzie jednak leży odpowiedzialność za decyzję o monetyzacji danych? Jak określić, czy w ogóle organizacja chce monetyzować dane? To przecież ważna decyzja, którą trzeba podjąć na pewnym etapie rozwoju organizacji i świadomości biznesowej. Czy podejście Data Driven wymaga, by tworzyć rolę Chief Data Officera, który jest partnerem zarówno dla CIO, jak i CMO na poziomie zarządu? Czy może taka odpowiedzialność powinna spoczywać w biznesie, ponieważ monetyzacja danych jest elementem modelu biznesowego? Czy potrzebna jest osoba, która stymuluje zarząd do rozmowy z technologią i z biznesem o architekturze tego podejścia?
Dodałbym jeszcze pytanie: kiedy w ogóle pojawia się moment, że w firmie zaczyna się dyskutować o monetyzacji danych?
Krzysztof Chibowski: W moim przekonaniu katalizatorem takiej rozmowy jest konkurencja. Jesteśmy w momencie, kiedy z peronu odjeżdża kolejny pociąg w kierunku szeroko pojętego AI. Czas wątpliwości i dyskusji minął. Pociąg zabiera firmy-pasażerów na wyższy poziom. Ci, którzy zostaną na peronie, bez wątpienia przegrają. Konkurencja użyje przeciw nim narzędzi LLM. Będą potrafili wykorzystać model do stworzenia zwycięskiej strategii i jej wdrożenia.
Chciałbym podkreślić, że jeśli ktoś myśli, że obecny moment zwrotny w adaptacji technologii związanych z szeroko pojętym AI i LLM go nie dotyczy, że w jego branży to się nie wydarzy, to jest w poważnym błędzie. „Później” już nie będzie. Aktualne jest hasło „AI or die”. Pora wziąć się w garść i zmierzyć z tą technologią, zrozumieć ją, zainwestować w kompetencje.
Tomasz Rychter: Mam podobne obserwacje. Niestety, w państwowych organizacjach nie ma podejścia dopuszczającego eksperymentowanie. Korzystamy z pieniędzy podatnika, więc musi być konkretny cel. Trzeba stosować prawo zamówień publicznych.

HPE kompletuje środowisko do zarządzania danymi. Jest to reakcja na sytuację na rynku, m.in. na efekty strategii Cloud First. Takie podejście przyniosło rozczarowanie szeregowi firm przenoszących hurtem rozwiązania on-premise do chmury obliczeniowej – Krzysztof Chibowski, Advisory and Professional Services, Hewlett Packard Enterprise.
Jesteśmy instytucją gospodarki budżetowej, to znaczy, że nie możemy zarabiać, a zatem nie mamy przychodów z zewnątrz. Moim zadaniem było uruchomić takie otwarcie poprzez projekt u pierwszego klienta biznesowego. Jest nim wspomniana Prokuratoria, która przystała na taki projekt. Wokół niego zaczęliśmy budować kompetencje zespołu.
W oparciu o zebrane doświadczenie i kompetencje będziemy mogli określić, czy jesteśmy Data Driven, czy zmierzamy w tę stronę. Bez wątpienia mamy dane. Bardzo ważne abyśmy mieli szanse dokończyć całościową ich inwentaryzację. Jestem przekonany, że część zasobów, np. raportów, będzie wymagała zaledwie niewielkich udoskonaleń, aby podnieść wartość dla organizacji. Podobnie w przypadku źródeł danych.
Leszek Chwalik: Moim zdaniem pierwsze pytanie ma podstawowe znaczenie: Kto jest właścicielem? Kto jest odpowiedzialny? Jest tylko jedna, możliwa odpowiedź – biznes. Biznes określa, że potrzebuje pewnych danych, że pomogą mu realizować cel. Odpowiada wówczas także za ich jakość przy akwizycji. I wreszcie on także dojrzewa do tego, aby rozpocząć ich monetyzację.
Biznes w Grupie Tauron jest świadomy, ponieważ posługujemy się cennikami usług. Rozliczamy się z ich dostarczania. Z góry możemy określić, ile będzie kosztować realizacja potrzeb biznesu. Poziom tej świadomości jest coraz wyższy.
Testem dla jakości i dojrzałości zarządzania danymi dla firm energetycznych jest wymóg gromadzenia danych na potrzeby Centralnego Systemu Informacji Rynku Energii – CSIRE. Ujawni on jakość, terminowość danych. Unormowanie ich jakości w tym zbiorze otworzy operatorom z większymi kompetencjami możliwość rozwinięcia kolejnych usług. Będzie to czynnikiem skokowej innowacji w różnych obszarach, jeśli np. zmiana sprzedawcy trwająca dziś 21 dni w nowym modelu ma być finalizowana w ciągu 24 godzin. Wyobraźmy sobie, jakie to wyzwanie dla procesów biznesowych i IT.
Dariusz Gregorczyk: Kwestia umiejscowienia i objęcia odpowiedzialności jest dla mnie podstawowym miernikiem dojrzałości organizacji w obszarze danych. I nie ma też jednej odpowiedzi, gdzie to powinno być umiejscowione, bo to zależy od organizacji. Natomiast to powinna być decyzja świadoma.
W wielu organizacjach obszar danych „przylgnął” do IT, na podstawie ogólnej zasady, że jeśli jest coś technologicznego, nieznanego, ze specyficznym językiem, to należy to przypisać IT. Trudno w tym przypadku mówić o świadomej decyzji. Może zdarzyć się, że odpowiednia komórka powstanie w biznesie, spontanicznie, ponieważ ktoś odkrył i rozwinął tam temat danych. Także wówczas trudno mówić o świadomej decyzji. Zależnie od organizacji, umiejscowienie może być różne: w e-commerce, marketingu, dziale zarządzania łańcuchem dostaw. Trudno mówić o przeciwskazaniach, poza tym, aby nie zabrakło przestrzeni do rozwoju.

Aby myśleć o Data Driven robimy remanent danych. Dookoła danych zaczęliśmy budować zespół i kompetencje. Jest to konieczne do efektywnego wypełniania roli doradcy dla Ministerstwa Cyfryzacji. Dane mają też służyć poszczególnym resortom i urzędom – Tomasz Rychter, dyrektor Pionu Innowacji i Jakości, Centralny Ośrodek Informatyki.
Dla mnie modelowym jednak jest CDO na poziomie zarządu, ponieważ wówczas sprawowana jest rzeczywista odpowiedzialność za obszar danych w szerokiej perspektywie całej firmy. Pozwala to zarazem koordynować współpracę między technologią a biznesem.
Jeżeli CDO jest w zarządzie, to z dużym prawdopodobieństwem świadczy to o tym, że organizacja jest dojrzała i ma świadomość budowania obszaru, który jest przestrzenią łączenia wiedzy biznesowej z wiedzą techniczną. Nie koncentrujemy się bowiem wówczas na aspektach technicznych i „zabawkach” dla biznesu, ale holistycznie patrzymy na wartość dla firmy.
To koncepcja odejścia od domenowego budowania wiedzy o firmie, praktyk, procesów.
Krzysztof Chibowski: Wobec takiego całościowego podejścia obok CDO pojawia się miejsce na kolejną rolę – Chief AI Officera (CAIO). Jest on odpowiedzialny za śledzenie rozwoju technologii sztucznej inteligencji i walidację ich przydatności. Takie stanowisko, które ma zapobiegać też ucieczkom z biznesowego peletonu, funkcjonuje już na niektórych rynkach.
Piotr Hołownia: To jest bardzo ciekawy wątek. Dane i AI będą wymuszały współpracę. Już nie da się operować domenowo, nie da się działać w granicach silosu, czy to IT, czy marketingu. Trzeba nieustannie optymalizować system. W innym wypadku dochodzi do przestojów i korkowania biznesu. Wspólne spojrzenie pozwoli zgrywać moce i zasoby logistyczne do obsługi cyfrowych kanałów sprzedaży.
Pozostając w swojej domenie, dzięki AI i danym, można zarazem budować współpracę w całej organizacji. Dodatkowym czynnikiem wsparcia takiej współpracy jest obecność i aktywność członka zarządu odpowiedzialnego za te obszary.
Tomasz Rychter: Współpraca pomiędzy obszarami to w tym kontekście niezbędny zabieg. Pozwala przezwyciężyć w sferze publicznej podstawowe niedogodności takie, jak brak finansowych KPI. Wiele ułatwia i podnosi uważność.
Chciałbym jednak zwrócić uwagę na problem, wobec którego stanie organizacja. Nie są to tylko obszar danych i AI. Jak Chief Data Officer i jego zespół zabezpieczy firmą przed sytuacją, w której wykorzystywany interfejs konwersacyjny generatywnej AI się pomyli? Jeśli użytkownik nie będzie świadomy, że dostał odpowiedź, która jest false positive? Odpowiedź na predykcje dotyczącą np. zaplanowania łańcucha dostaw może być przekonująca, ale nieprawdziwa.
Piotr Hołownia: Pracujemy właśnie nad tym problemem. Jest wiele metod korzystania z dużych modeli językowych (LLM). Punktem wejścia jest upewnienie się, że model kieruje zapytanie do właściwej części bazy danych. Załóżmy, że chcemy użyć LLMa do wsparcia w przygotowaniu dokumentu prawnego. Warto, żeby model miał na wejściu reguły lub proces interakcji z użytkownikiem ukierunkowujący uzyskanie odpowiedzi z właściwych obszarów naszych danych. W ten sposób do bazy prawnej można zadać o wiele więcej zapytań niż w sytuacji, gdyby model wertował każdorazowo zawartość całego zbioru. Zwiększa to jakość odpowiedzi modelu i minimalizuje czas interakcji potrzebny do uzyskania odpowiedzi.
Jakiś czas temu przeniesienie danych do chmury miało być uniwersalną receptą na wszystko, także na bałagan w danych. Oczywiście wiemy, że w chmurze pozostanie bałagan, tylko droższy. Wraz z udostępnieniem ChatGPT pojawiła się wiara, że on wszystko załatwi – Dariusz Gregorczyk.
Mówimy tu chyba o Data Asset Management, które pozwalają podzielić zasoby danych do różnych specjalizowanych modeli. One siłą rzeczy są domenowe, aby były efektywne.
Piotr Hołownia: Ewolucja dużych modeli językowych będzie zmierzać w stronę specjalizacji. Całkowicie niezależnie od dostarczanych przez gigantów rynku omnibusów, które będą wiedziały wszystko i… nic.Powiedzmy, że do zastąpienia dzisiejszej wyszukiwarki internetowej w prostszych zapytaniach np. o przepis na najlepszą pizzę będą wystarczające. Ale to biznesu nam nie pozwoli zrobić. Trzeba w przemyślany sposób przygotować bazy danych i dostroić model do określonej specyfiki biznesowej.
Dariusz Gregorczyk: To słowo „nic” jest kluczowe, ponieważ pozwala rozbroić pewną pułapkę, w którą łatwo popaść. Jakiś czas temu podobna pułapka kryła się za pojęciem chmury. Przeniesienie danych do chmury miało być uniwersalną receptą na wszystko, także na bałagan w danych. Oczywiście wiemy, że w chmurze pozostanie bałagan, tylko droższy w utrzymaniu. To samo dotyczy doświadczeń z algorytmami AI, ML.
Mieliśmy stabilny, ciekawy wzrost tego obszaru do października 2022 roku. Potem nastąpił boom w związku z ChatGPT i pojawiła się znowu wiara, że to wszystko załatwi. Bez wizji do czego chcemy to wykorzystać. Bez indywidualnej pracy zamykamy się w bańce, bo algorytmy są uczone na konkretnym zestawie danych.
Leszek Chwalik: Myślę, że są dwie prędkości w adaptacji generatywnej AI – wiara i optymizm oraz opór. Dla pewnej grupy stanowisk czy funkcji charakterystyczna jest obawa, że efektywne, wiarygodne wykorzystanie AI zabierze miejsca pracy. Ten opór jest czymś naturalnym. Staramy się go przełamywać, oswajać, oferując np. podnoszenie kwalifikacji.
Jest też drugie podejście warunkowane przez chęć poznawania czegoś nowego. W tej, nowej domenie, trzeba podejście do danych budować od fundamentów – mentalności, kultury korzystania tej technologii. Nie stymuluje tej zmiany linia biznesowa, tylko obszar, który dostarcza, integruje i ukierunkowuje wykorzystanie technologii AI. To jest nastawienie na poszukiwanie możliwości współpracy, ale i wyszukiwania sposobów monetyzacji na bazie tej współpracy. To właśnie nowe podejście w wykorzystaniu danych jakie niesie adaptacja AI.
Nie wyklucza to więc w żadnym wypadku znaczenia czynnika ludzkiego. Sądzę, że w przypadku wykorzystania AI w biznesie, zawsze pozostaniemy nieufni. To będzie praca – predykcje, analizy, rekomendacje decyzji, odpowiedzi na zapytania – wykonywana na cztery ręce, weryfikowana przez człowieka. Przykładem jest rozwój sytuacji w sektorze zdrowia, gdzie AI pozostaje elementem wspomagającym, a nie przejmującym podejmowanie decyzji.
Piotr Hołownia: Jeżeli mówimy np. o tym, że za pośrednictwem LLM każdy będzie mógł wykonać zapytanie do bazy danych, czy to znaczy, że stanowiska “analityków danych” przestaną istnieć? Nie, wciąż będą istnieć tylko ewoluują do innej postaci, np. Prompt Engineer’ów. Czy może LLM same będą się utrzymywać? Nie, na pewno przez jakiś czas trzeba będzie zespołu ludzkiego tak, który będzie pracował nad doskonaleniem i rozwijaniem modelu
Natomiast warto zastanowić się strategicznie nad tym czy zespoły technologiczne odpowiedzialne za generatywną AI powinny skupić się nad poprawnością i efektywnością działania modeli i baz danych czy raczej nad budowaniem precyzyjnych zapytań i uzyskiwaniem użytecznych wyników od modeli językowych.
Jesteśmy właścicielem różnych danych z obszaru wytwarzania, sprzedaży, dystrybucji. Chcemy pozyskiwać i agregować też dane zewnętrzne. Skorelowane, dostarczyłyby przełomowych informacji dla nas i klientów. Pozwoliłyby osiągnąć nowy poziom zarządzania i kreowania biznesu, predykcji – Leszek Chwalik.
Sądzę, że nawet zautonomizowane modele LLM jeszcze dość długo nie prześcigną znających nasz biznes ekspertów w formułowaniu, projektowaniu zapytań służących uzyskaniu unikalnych, wiążących biznesowo odpowiedzi. Bez wątpienia jednak już teraz stanowią niezwykle wydajne wsparcie ich pracy.
Dariusz Gregorczyk: Ale znowu wchodzimy w ryzyko ulegania pokusie wykorzystywania AI poza ramami, zdefiniowanymi zasadami i celami. Nieprzypadkowo wspomniałem, na jakim etapie jest Empik. Ludzie chętnie korzystają z technologii – mając tylko taką możliwość mogą wejść w ten świat bardzo głęboko. Jednak przy braku nadrzędnej koncepcji może pojawić się taki moment, że musimy zrobić dwa kroki w tył. W biznesie to kosztuje.
Kto z nas nie był świadkiem dyskusji przed zarządem o rozbieżności danych w różnych raportach? Paradoksalnie często takie dyskusje dotyczą rzeczy pozornie łatwo policzalnych: jak liczba sklepów w sieci handlowej czy liczba klientów w sprzedaży B2B. To efekt tego, że świadomość konieczności stworzenia słownika pojęć pojawiła się w danej firmie zbyt późno. W dobie AI pojawia się pokusa, że ktoś – bez znajomości języka zapytań – będzie wolał odpytać zewnętrzne źródło o informację, która powinna być określona jasno w firmie.
I wracamy do kwestii odpowiedzialności biznesowej za wybór danych. Za biznesową „krytykę źródeł”, na wzór procesów z metodyki np. historyka. Dość dokładnie przetestowałem aktualnie najpopularniejsze modele AI i wiem, że o ile proste zapytania z reguły nie sprawiają problemu to nieco bardziej skomplikowane zwracają nieprawidłowe wyniki. Nie wspominając o naprawdę złożonych pytaniach. Dziś jestem w stanie to dość łatwo wyłapać, ale za jakiś czas, po przekroczeniu tej cienkiej linii, gdy modele staną się trochę lepsze ode mnie, już tego tak łatwo nie uczynię. Pamiętajmy przy tym, że żyjemy w świecie „good enough”, więc nie ma pewności czy rozwój modeli po przekroczeniu tej linii nie spowolni.
Pojawia się także problem właściwego sformułowania zapytania w języku naturalnym. Jeśli go nie pokonamy, tylko zaakceptujemy to ryzyko, to ono się zmaterializuje i będziemy operować na zafałszowanych wnioskach. To niesie ryzyko błędnych decyzji. W firmie handlowej konsekwencją będzie strata albo stagnacja sprzedaży. Natomiast w sektorach kluczowych – jak energetyka – efektem może być nawet utrata ciągłości działania.
A to prowadzi nas ponownie do zagadnienia odpowiedzialności za rozwiązanie, za zgodność i jakość modelu, który został wystawiony do biznesu.
Krzysztof Chibowski: Można zaryzykować stwierdzenie, że od danych jeszcze ważniejsze są metadane. Dobrze znać źródła danych, ale wymagają one opisu – kto jest właścicielem, gdzie leżą, jaka cechuje je retencja, krytyczność czy czułość. Odwiedzam dziesiątki firm w Polsce i za granicą, i widzę, że prawie nikt o to nie dba. Trudno nawet zmierzyć, jak wiele danych w organizacjach jest zdublowanych, a za to wszystko trzeba przecież płacić.
Artur Studziński: Taka nieefektywność przypomina start w wyścigu na bieżni w ciężkich butach, podczas gdy konkurenci biegną w kolcach. Ten, kto odrobi lekcję uporządkowania danych, zyska łatwość posługiwania się nimi, podczas gdy inne organizacje będą ciągle produkować wybrakowane raporty lub czekać na nie np. dwa lata. Albo po prostu uzyskiwać zafałszowane informacje.
Piotr Hołownia: Bardzo podobał mi się przytoczony przykład z nieznaną liczbą sklepów, bo to problem typowy dla dużych organizacji. Po prostu wszyscy wiemy, że powstaje np. 6 raportów na jeden temat, które pokazują różne wartości. W efekcie trzeba się zdecydować, czy to akceptujemy, czy poszukujemy jednego źródła prawdy.
Wiele razy słyszałem obietnicę, że nowe rozwiązanie będzie miało taki właśnie charakter. Tylko zmigrujmy wszystko do jednej bazy, a będzie wspaniale. A potem okazuje się, że migracja trwa długo, następnie następuje etap strukturyzowania i porządkowania danych, ich przenoszenie itd. W efekcie nigdy do obiecanego ideału się nie dochodzi.
Jest jednak inny wybór. Może zamiast pościgu za nieuchwytnym celem spróbować zadbać o jakość danych i ich porządek. Zdefiniować 10 krytycznych parametrów biznesowych, które są dla nas ważne i pod tym kątem budować środowiska analityczne i raportowe.
Krzysztof Chibowski: Dotychczas dokonaliśmy oceny dojrzałości kilku tysięcy organizacji pod kątem umiejętności wydobywania wartości z danych. Są firmy, które reprezentują poziom 5, najwyższy, prowadzące biznes ściśle warunkowany liczbami, danymi, w czasie rzeczywistym. Ale są także firmy, które mają taki nieład w tej sferze, że trudno rozpocząć zmianę. Bywa, że pierwszy rok współpracy polega na rozmowach i wprowadzaniu klienta w temat. Po roku podejmuje on decyzję o zmianie, ale wsparcie dostawcy okazuje się niezbędnym impulsem.
Po wdrożeniu narzędzi Hadoop czy Spark, taka firma nagle dostrzega, że dane, które lądowały dotychczas „w piwnicy” przynoszą korzyści. Że firma może pozwolić sobie na mikrotargetowanie i inne – niemożliwe bez korelacji danych – działania marketingowe – Artur Studziński.
Dariusz Gregorczyk: Przy takich zewnętrznych rozwiązaniach pojawia się pokusa drogi na skróty. Jeżeli w firmie nie ma świadomości tematu, to z dużym prawdopodobieństwem pojawi się pomysł, aby szybko skopiować jakieś rozwiązanie, wdrożyć cokolwiek co symulowałoby wejście na drogę Data Driven. Szybki strzał, sukces, prezentacja na posiedzeniu zarządu, wdrożenie do końca roku i rozliczenie premii.
Znam przypadki, gdzie efektem było uzależnienie od dostawcy, które powodowało, że biznes się zatrzymywał. Wprowadzenie każdego nowego produktu wiązało się z wydatkami na dostawcę. Biznes był sparaliżowany. Brakowało pieniędzy na wdrażanie nowych produktów, ale i na zmianę systemu. Sztuką więc jest tak ułożyć współpracę, abyśmy realnie czerpali z tego, co dostawca może nam przynieść, bo ma w tym zakresie szersze doświadczenie.
Tomasz Rychter: Aby uniknąć tego niebezpieczeństwa zaczęliśmy od intensywnego budowania wewnętrznych kompetencji. Od początku towarzyszyli nam też dostawcy, przedstawiając gotowe rozwiązania. Jednak na tym początkowym etapie nie bylibyśmy nawet w stanie w rzetelny sposób odebrać wdrożenia. Bez silnych kompetencji nie stać byłoby nas na stwierdzenie tego, ani na asertywną postawę wobec nierzetelnych partnerów.
Próg wejścia nie jest przy tym bardzo wysoki. Nie potrzeba 200 wysokospecjalizowanych pracowników, ale przynajmniej kilku, kilkunastu bardzo doświadczonych, którzy nadadzą pracy innych kierunek i oparcie. Nie będą też unikać kontaktu z dostawcą. Jest to także powszechna przypadłość sektora publicznego, ponieważ ma uchronić od posądzenia o to, że kontakt doprowadził do jakiegoś nieuzasadnionego, nieuczciwego promowania rozwiązania.
Nie można jednak zamykać się na dostawców. Trzeba z nimi rozmawiać. Poznawać bardzo dobrze ich rozwiązania, bo dopiero wtedy możemy rozważyć co chcemy i możemy wykorzystać. Często w tym wypadku oferowana jest bezpłatna asysta dostawcy. Ale wiemy, że nie ma „darmowych obiadów”. Zawsze kryje się za takim układem ryzyko uzależnienia, które wymagałoby dokupowania w ciemno kolejnych rozwiązań.
Nie uważam, że zawsze sami jesteśmy w stanie zbudować coś lepiej. Chociaż mogą być też takie przypadki. Obszar modeli LLM i NLP stwarza takie pole. Język polski nie jest dobrze obsługiwany w takich rozwiązaniach. Potrzeba chociażby właściwego uchwycenia wieloznacznych kontekstów, nie wspominając o gramatyce.
Więc naprawdę trzeba bardzo rozsądnie podchodzić do współpracy z partnerem. Nawet jeżeli biznes ma uzasadnione oczekiwania, aby wdrożyć coś szybko, trzeba przekonać go do tego, by zrealizować to świadomie i bezpiecznie, w oparciu o wewnętrzne kompetencje.
Leszek Chwalik: W moim przekonaniu, bez biznesowej iskry technologia będzie bezużyteczna. Inicjatywa musi wynikać z pomysłu biznesu. Ale też nie obawiałbym się dostawcy, dopóki biznes – we współpracy z IT – jest w stanie pokierować jego wsparciem dla swojego pomysłu. Wówczas biznes weryfikuje korzyści własnym językiem, a IT określa, ile będzie kosztowała technologia i jej utrzymanie rozwiązania. Dlatego uważam, że jeśli biznes chce, to trzeba mu dać szansę. Natomiast biznes musi chcieć. Musi kreować pomysły, poszukiwać sposobów na „zarobienie” pieniędzy.
Dane i AI będą wymuszały współpracę. Już nie da się operować domenowo, nie da się działać w granicach silosu, czy to IT, czy marketingu. Trzeba nieustannie optymalizować system. W innym wypadku dochodzi do przestojów i korkowania biznesu – Piotr Hołownia.
Artur Studziński: W świecie idealnym biznes wie, czego chce i przekazuje IT jakiego narzędzia potrzebuje. Mogę jednak przytoczyć różne przykłady firm, w których dopiero wdrożenie uruchamia falę zmian. Po wdrożeniu narzędzi Hadoop czy Spark, taka firma nagle dostrzega, że dane, które lądowały dotychczas „w piwnicy” przynoszą korzyści. Że firma może pozwolić sobie na mikrotargetowanie i inne – niemożliwe bez korelacji danych – działania marketingowe. W efekcie biznes zaczyna wywierać presję na dalsze zmiany. Firma zaczyna zmieniać się w kierunku Data Driven, oszczędzając czas i pieniądze. Ostatnio jeden z takich klientów doszedł już do etapu wdrożenia Data Mesh.
Tomasz Rychter: To kwestia tego, aby uświadomić im, czego nie wiedzą, albo zachęcić do działania, bo są różne skale natężenia oporu. Akurat ja doświadczyłem bardzo dużej, kiedy przychodziłem do COI. Nie miałem poszukiwać innowacji, tylko zadbać o User Experience dla aplikacji publicznej. Uważałem, że minimalizm to nie jest dobry punkt wyjścia. Jednym z elementów budowy zespołu było więc zbudowanie komórki, która zajmuje się wyłącznie badaniami jakościowymi i ilościowymi.
W Centralnym Ośrodku realizujemy równolegle kilkadziesiąt dużych przedsięwzięć, a łącznie z mniejszymi portfel obejmuje kilkaset projektów. Podpisane umowy nie gwarantowały budżetu na badania. Ale kropla drąży skałę. Zaczęły pojawiać się pierwsze analizy. Udowadnialiśmy, że przynoszą dużo wiedzy i wskazówek.
Około roku trwało budowanie pozycji i znaczenia badań, których potrzeby nikt już nie kwestionował, tylko ich oczekiwał. Nastąpił przełom, uwarunkowany przekonaniem klientów biznesowych, że wnosimy wartość. COI nie jest jeszcze organizacją Data Driven. Natomiast obecność naszego departamentu, a z czasem pionu, sprawiła, że jest komu zadać pytanie o dane, analizy, statystykę.
Chciałbym jeszcze odwołać się do kwestii Governance. Kiedy to zaczyna dojrzewać, krzepnąć na tyle, aby można by było na tym opierać rozwój?
Krzysztof Chibowski: Do tej pory organizacje, szczególnie duże, opierały koncepcje architektoniczne dla różnych obszarów, w tym danych, na frameworkach. To były całe tomy wytycznych, wskazówek, rekomendacji. Mam wrażenie, że w ostatnich latach to gdzieś przepadło. Ale nie można dać się zwieść pozorom. One wciąż istnieją i są dobrą podstawą organizacji takich obszarów jak Data Management. Tam jest gotowy szkielet, zawierający ład, który powinien gwarantować zrównoważony rozwój i unikanie błędów.
Jedną z 9 domen Data Management jest Data Governance. To punkt odniesienia, który pozwala zrobić „rachunek sumienia” przed uruchomieniem większych zmian i wdrożeń. Źle, jeśli z tego nie korzystamy, odrzucając tę wartość, bo wydaje nam się, że zrobimy coś lepiej intuicyjnie.
Kiedy spotykam się z klientami, rozmowę zaczynam od białej tablicy. Opowieść o strategii, celach i potrzebach odnoszę do wiedzy ugruntowanej we wspomnianych rekomendacjach i standardach dla obszaru danych. I na tej podstawię staram się – wspólnie z klientami – stworzyć coś w rodzaju Digital Journey Map. Odnajdujemy, w którym punkcie tej podróży jest firma i kogo trzeba zaangażować w kolejnych krokach, aby tworzyć ład zgodny ze standardami. Do tego w ogóle nie potrzeba rozmowy o produktach.
W tej rozmowie często umyka moim partnerom, że reprezentuję konkretnego dostawcę. Rozmawiam z nimi o transformacji, która musi uwzględniać framework gwarantujący jakość na dziś i na dłuższy horyzont. Biznes z czasem to sobie uświadamia i zaczyna dyskutować, posługując się już wytycznymi, językiem frameworku. Z jakiegoś powodu nie jest to powszechne, choć dostępne, na wyciągnięcie ręki.
Opowieść o strategii, celach i potrzebach odnoszę do wiedzy ugruntowanej we wspomnianych rekomendacjach i standardach dla obszaru danych. I na tej podstawię staram się – wspólnie z klientami – stworzyć coś w rodzaju Digital Journey Map – Krzysztof Chibowski.
Dariusz Gregorczyk: Może dlatego, że te wytyczne mają 700 stron. Może warto rozważyć budowę modelu LLM, który będzie w stanie płynnie podpowiadać i weryfikować pomysły w odniesieniu do wytycznych.
Mówiąc o takiej konstrukcji procesów decyzyjnych, pozwolę sobie przywołać doświadczenie Reckitt Benckiser dotyczące zarządzania środowiskami chmurowymi. Ja postrzegam to jako element podejścia Data Driven w optymalizacji wewnętrznej.
Piotr Hołownia: Rzeczywiście, realizujemy proces, który pozwala na stałą ocenę środowiska chmurowego pod kątem kosztów, synergii, wartości itd. W tej chwili operujemy już w prawdziwym multicloud więc możemy szerzej spojrzeć na technologie chmurowe. Maksymalizujemy korzyści i możemy dla konkretnych procesów biznesowych rekomendować optymalne środowisko chmurowe.
Leszek Chwalik: Wówczas faktycznie zarządzasz całą architekturą biznesową. Pomimo skali tych środowisk, organizacja nie jest ich niewolnikiem, wdrożenie nie oznacza, że za 15 lat dana technologia niepodzielnie będzie dominować w jakimś obszarze. Widziałbym to jako coś pokrewnego, spójnego z podejściem Data Driven, ponieważ nadaje elastyczną kulturę i architekturę firmie.
Sektor publiczny może mieć trudności we wprowadzeniu takiego podejścia, szczególnie jeśli posłuży się finansowaniem z Unii Europejskiej, które zawiera klauzule dotyczące trwałości projektu. To jest istotne utrudnienie decyzyjne, ograniczenie elastyczności, ale wymaga zarządzania i przezwyciężenia, ponieważ koszty i nakłady inwestycyjne z roku na rok w obszarze technologicznym rosną.
Krzysztof Chibowski: To dobry moment, aby wrócić do kwestii odpowiedzialności i świadomości wpisanej w korporacyjne role. Wspominane tu dziś stanowisko CDO posiada dwie definicje: Chief Data Officer, ale też Chief Digital Oficer. W obu przypadkach w zakres działalności, czy odpowiedzialności, wchodzi nadzór nad Data Management. Niekiedy nawet Data Governance plasuje się ponad Data Management. Ostatecznie jednak każda architektura czy środowisko mają rolę służebną. Mają one umożliwić realizację potencjału zawartego w gromadzonych danych.
Dariusz Gregorczyk: Myślę, że w praktyce często rozbijamy się o świadomość. Łatwo mówić o Data Governance na poziomie frameworków i teorii. Nie widzę jednak innej możliwości ani celu wdrażania Data Governance, jeśli nie jest on zgodny, nie wynika wprost z realizacji strategii firmy. Tak jak nie mamy do czynienia z teoretyczna strategią, tak nie możemy posługiwać się teoretycznym Data Governance.
Jaką możemy sformułować zatem konkluzję w odniesieniu do tematu debaty? Czy firmy w Polsce są już dalej na drodze do podejścia Data Driven? Czy w ciągu pół roku mają szansę lub wymóg wywindować ten rozwój wyżej?
Krzysztof Chibowski: Wydaje mi się, że to powinno się rodzić wewnętrznie na bazie obserwacji rynku, ale nie jako wyraz podążania za rynkiem czy strachu pozostania poza głównym nurtem. Chodzi o budowę i upowszechnienie przekonania, że dane mają znaczenie i istnieją narzędzia do ich wykorzystania.
Kto w sektorze publicznym będzie prowadził Data Governance i zapewni, aby synergia danych posłużyła wszystkim? Planowana jest wymiana danych pomiędzy różnymi sektorami. Ich połączenie, zderzenie, obiecuje wielowymiarowe korzyści – Tomasz Rychter.
Z tym przekonaniem warto pokusić się o inwentaryzację, która określi obecne i docelowe miejsce firmy na marszrucie do Data Driven Enterprise. Ta analiza powinna ośmielić także do działań sanacyjnych, kiedy potrzeba wykonać krok lub dwa wstecz, naprawić fundamenty, wstrzymać pochopnie zainicjowane projekty, które wprowadzają narzędzia nieadekwatne do poziomu dojrzałości organizacji.
Pół roku to zbyt krótki czas, aby taki proces się wydarzył. Jeżeli jednak zaczniemy teraz, to będzie to zarazem dostatecznie długi czas, aby dostrzec różnicę i uzyskać przekonanie, że warto taką podróż kontynuować.
Tomasz Rychter: W sektorze publicznym pół roku to czasami bardzo dużo, niekiedy wręcz mgnienie oka. W COI zależy to od tego, czy mówimy o procesach wewnętrznych, czy zewnętrznych, np. przedsięwzięciach międzyresortowych. Największe wyzwanie to właśnie współpraca międzyresortowa, bo tam występuje najwięcej spowalniaczy. Podstawowe pytanie w odniesieniu do danych dotyczy zasad, na których w ogóle możemy je przetwarzać.
Natomiast na poziomie samej organizacji pół roku to bardzo dużo i pozwoli nam na pewno zrozumieć gdzie jesteśmy. Będziemy bardziej dojrzali niż teraz, ponieważ zaczęliśmy właśnie podobny „remanent”. Łatwiej jest nabierać dojrzałości na wczesnych etapach, później ten rozwój przyhamowuje. Trzeba też świadomie opierać się pokusie skracania ścieżek, szczególnie w obliczu wykładniczego postępu technologicznego. Żaden cudowny algorytm nas nie zbawi. Musimy zacząć od tego, żeby porządnie odrobić zadanie domowe.
Dariusz Gregorczyk: W handlu pół roku to bardzo dużo. To jest szybki biznes, gdzie dużo się zmienia. Nie ukrywam, że właśnie teraz snop mocnego światła padł w tym sektorze na obszar danych. Rodzi to wielkie oczekiwania i nadzieje. Ale, podobnie jak Tomasz, zwrócę uwagę na wymóg budowy świadomości. A świadomość to już jest inny proces, ponadbranżowy i ona się tak szybko nie zmienia. Z tego wynika, że nie spodziewam się abyśmy doczekali się przełomu w tak krótkim horyzoncie czasowym w skali makro. Natomiast niewątpliwie będą na rynku gracze, którzy przełożą wspomnianą świadomość na konkretną wizję i strategię działania. Jeśli zrobią to umiejętnie, mają szansę na istotny skok.
Piotr Hołownia: Pół roku to jest dużo i mało. Natomiast z pewnością jest jedna rzecz, która wymusza na nas reakcję w tym okresie. To kwestia zmian jakie do biznesu wnosi zastosowanie modeli LLM i ogólnie, wszystkich rozwiązań AI. One pracują na danych, które posiadamy. One zaczną eksplorować bazę danych, generować pewne obserwacje i wnioski dla biznesu. Pojawią się też pętle zwrotne, oceny efektywności i jakości wniosków budowanych na bazie naszych danych.
Uważam, że najbliższe pół roku wykorzystamy jako firma tę szansę, aby „pociąg” AI nie odjechał bez nas. Ale to nie będzie podróż w roli pasażera-turysty Orient Ekspresu, tylko raczej ciężko pracującego palacza parowozu. Zacznie się ostra, bezwzględna weryfikacja danych i procesów zarządzania danymi w firmie. I zgadzam się, że obecne półroczne okienko czasowe jest kluczowe. To rzeczywiście jest „ten czas”.
Leszek Chwalik: Na pewno za pół roku będziemy w innym miejscu niż dziś. Częściowo z własnej woli, częściowo unoszeni prądem tego, co dzieje się na rynku. Są to zarazem procesy długotrwałe, długofalowe i kosztowne. Dzisiaj mówiliśmy przede wszystkim o obszarze IT, podczas gdy na zagospodarowanie czekają rozległe obszary OT.
Zmiany prawne z pewnością będą stymulowały rynek do aktywności w obszarze danych. Natomiast nie mamy ambicji ścigać się z innymi. Stawka jest duża, ryzyka poważne, zarówno widoczne, jak i ukryte. Mamy zadanie budowania kompetencji, świadomości, wartości posiadanych danych. Na pewno będziemy za pół roku w innym miejscu.
Artur Studziński: Rozmawialiśmy o tym, że zagadnienie danych rozchodzi się po całych firmach. To nie tylko temat dla marketingu, e-commerce czy innych działów. Będziemy obserwować rewolucję, która będzie się dokonywać w najbliższych 6 miesiącach, pewnie także dłużej. I albo się do niej ustosunkujemy, albo ta wielka zmiana przejdzie obok nas.
To nie będzie zarazem nic nadmiernie spektakularnego, ale w użycie powszechnie wejdą wszelkie narzędzia wspomagające pracę, jak co-pilot czy auto-pilot. Firmy będą dostrzegać, jaki wpływ nowe narzędzia mają na efektywność zarówno w skali mikro, jak i makro.
Jak wspomniał Krzysztof, 80% danych było dotąd w formie nieustrukturyzowanej, zupełnie wyłączone z automatyzacji. Były narzędzia NLP, które w jakimś stopniu pomagały przejść tym danym tekstowym na strukturę danych zrozumianą dla uczenia maszynowego. Natomiast modele LLM zmieniają zasady gry. Wymagają jednak mocy obliczeniowych, ładu i procesów. To jest kolejnym aspektem tej rewolucji. Według mnie to pełzająca, niedostrzegalna z bliska rewolucja, podobna do elektryfikacji.
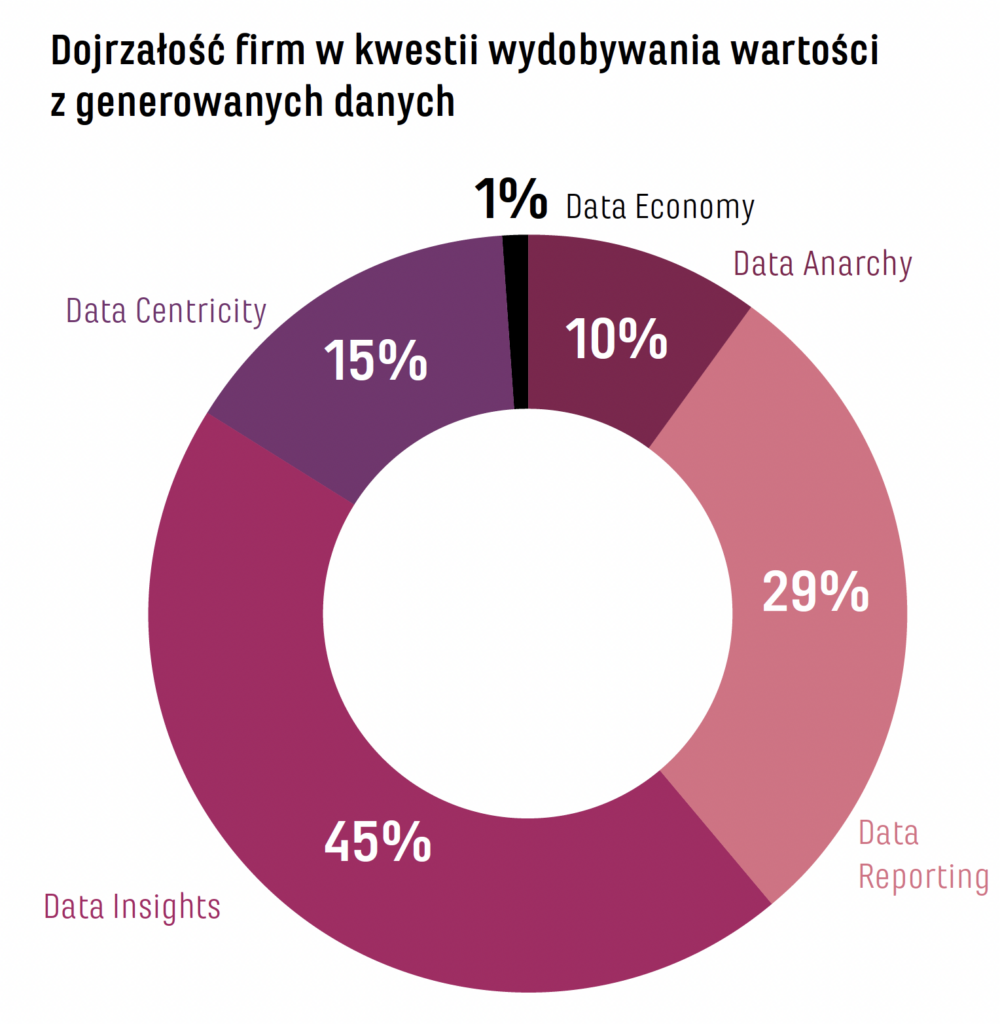 Źródło – Hewlett Packard Enterprise
Źródło – Hewlett Packard Enterprise





