

W coraz bardziej zdigitalizowanym świecie firmy, bez względu na branżę, muszą odpowiedzieć na pytanie, jak zarządzać danymi biznesowymi? Ma to bowiem bezpośredni wpływ na ich wydajność i trafniejsze decyzje kierownictwa. Zarządzanie danymi w firmach wchodzi na coraz wyższy poziom abstrakcji, dlatego coraz trudniej poradzić sobie z tym zadaniem bez wiedzy i wsparcia doradców. Nowe potrzeby biznesowe zmieniają podejście do zarządzania danymi i kreują nowy trend demokratycznego Data Mesh.

Od ponad 40 lat sprawdza się idea hurtowni danych. Zbiory danych były projektowane pod konkretne cele, przed wprowadzeniem do nich informacji. Takie podejście było odpowiedzią na powstające już w latach 70. XX wieku bazy (np. transakcji bankowych), zoptymalizowane pod kątem obsługi miliardów krótkich transakcji, w których wykorzystuje się małe fragmenty danych, ale dalekie od ideału w razie dłuższych zapytań analitycznych. Do tego potrzebny był inny silnik pamięci masowej i danych. Doprowadziło to do pojawienia się hurtowni danych.
Etap 1: hurtownie danych z mechanizmem ETL
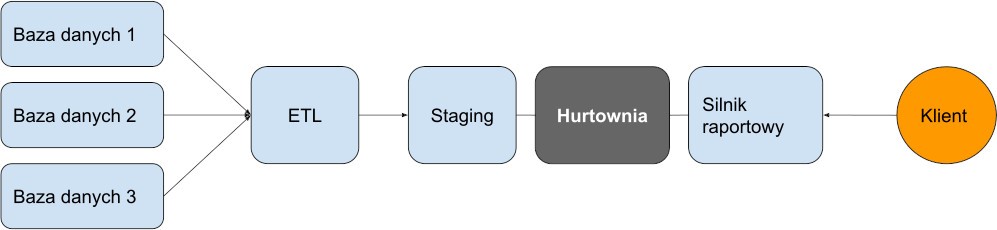
Hurtownie danych są tradycyjnie zoptymalizowane pod kątem faktów i posiadają wymiary odpowiednie do zaplanowanego wcześniej zestawu zapytań. Klasycznym przykładem takiego wykorzystywania zbioru danych są np. miesięczne raporty sprzedaży, dla każdego oddziału firmy w jakimś okresie czasu. Najczęstszym narzędziem do pozyskiwania danych na potrzeby hurtowni danych jest Extract-Transform-Load (ETL). ETL to wyciąganie danych ze źródłowych baz, przekształcanie ich (oczyszczanie, filtrowanie wstępne i agregowanie) oraz ładowanie do magazynu. Proces, który prosto wygląda na schemacie, nigdy nie jest łatwy w realizacji i w pracy programistów zawsze wprowadza wysoki poziom stresu.
Rysunek 1: schemat działania mechanizmu ETL w hurtowni danych
Etap 2: silosy zalały jeziora danych
Model hurtowni cały czas sprawdzał się w warunkach dobrze znanych i stabilnych potrzeb. Ale szybkość operacji biznesowych, liczba źródeł danych nierelacyjnych i zmienność potrzeb analitycznych szybko rosły m.in. pod wpływem technik uczenia się maszynowego (Machine Learning). Hurtownie danych z ich utartymi schematami i skostniałą strukturą po wypełnieniu ich terabajtami danych stały się wrogiem lepszego. Na dodatek różne grupy użytkowników biznesowych – ze swoimi specyficznymi potrzebami raportowymi i analitycznymi – tworzyły własne hurtownie z mechanizmami ETL, wykorzystując różnych dostawców i różne systemy analityczne. Dane, zarówno surowe, jak i przetworzone, były przez to przechowywane w różnych systemach. Tak tworzyły się silosy danych na różnych poziomach działów firmy.
Nie była to komfortowa sytuacja dla działów IT. Rosła potrzeba posiadania wszystkich danych firmy w jednej centralnej lokalizacji, w której mogłyby być zarządzane przez zespół centralny oraz przechowywane w surowym, niezmienionym formacie, aby umożliwić ich późniejsze przekształcanie. Zamiast projektować bazy danych należało zebrać wszystkie możliwe źródła danych, a użytkownikom przekazać tylko narzędzia do analizy i informacje, jakie dane znajdują się w jeziorze (Data Lake). To było wywrócenie dawnego modelu do góry nogami. Możliwość wręcz dowolnego przeszukiwania Big Data była odpowiedzią na rosnącą potrzebę wydobywania z wszystkich dostępnych danych nowych informacji i wiedzy.
Rysunek 2: schemat Data Lake
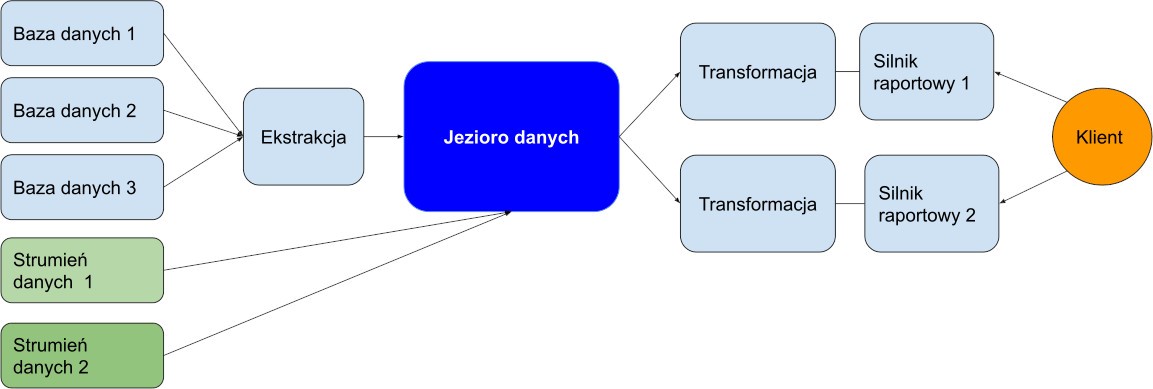
W jeziorze danych „pływają” dane ze wszystkich dziedzin biznesowych i wszystkich części organizacji, zebrane w jednej lokalizacji. Można wydobyć, załadować, a następnie przekształcić (ELT) dane w obecnych i przyszłych celach analitycznych. Dane są w surowym formacie, więc nie ma ryzyka, że coś zostanie utracone. Żadna informacja nie ulegnie też zniszczeniu w trakcie tego procesu.
Konsumenci mogą zdecydować, w jaki sposób chcą korzystać z danych przechowywanych w Data Lake teraz i w przyszłości. Natomiast dział IT może dodawać nowe źródła danych i wypełniać nimi jezioro. Zespół centralny zarządza zaś różnymi widokami i mechanizmami dostępu. Dzięki temu dane – mimo że znajdują się w jednym miejscu – są chronione przed nieautoryzowanym dostępem. Dodatkowo technologie strumieniowej transmisji danych umożliwiają raportowanie w czasie rzeczywistym i stałe pobieranie danych do Data Lake. Odpowiednie zaprojektowanie jezior danych umożliwia narzędziom bazującym na chmurze wnioskowanie schematu z danych i wykorzystywanie ich do obsługi złożonych zapytań. Możemy postrzegać te narzędzia jako półautomatyczne hurtownie danych, ale w nowoczesnej, elastycznej wersji.
W Data Lake wszystko jest przechowywane „na wszelki wypadek”, ale nikt nie wie dokładnie w jakim celu. Niestety przechowywanie danych w jednym miejscu nie czyni ich bardziej zrozumiałymi. A ilość danych gwałtownie rośnie. Jak poradzić sobie z tym zalewem bez właściwego zrozumienia, które dane mają znaczenie, a które nie? Pracy nie ułatwia też surowy format danych. Jeśli konsument danych chce coś z nimi zrobić, to sam musi przeprowadzić transformację danych na bardziej cywilizowany format. Ponadto osoby zarządzające jeziorem danych (Data Engineers) są często odizolowani od zespołów biznesowych, nie znają praktyki biznesowej firmy i nie mają wiedzy biznesowej o danych. Na dodatek wszystkie działy są zależne od jednego zespołu Data Engineers.
Etap 3: demokracja w Data Mesh
Systemy biznesowe ewoluowały w kierunku mikrousług, ale w obszarze danych nadal dominowała i dominuje centralizacja. Jezioro danych może być postrzegane jako monolit, który – tak, jak hurtownie danych – po pewnym czasie zaczął przeszkadzać w analizach. Potrzeba opracowania nowego sposobu przechowywania danych doprowadziła do powstania podejścia Data Mesh. Dzięki temu strumienie i zbiory danych są własnością użytkowników. Są to dane surowe, a nie operacyjne z baz źródłowych. Można je przekształcić w celu stworzenia wspólnego, zagregowanego widoku dla wybranej dziedziny biznesowej. Niezależne zespoły współpracujące z ekspertami biznesowymi mogą teraz lepiej zrozumieć znaczenie danych w celu wygenerowania bardziej trafnych wniosków i przewidywań. Brzmi trochę tak jakby nowym rozwiązaniem było przywrócenie dawnych problemów i tworzenie silosów. Na szczęście przyszłość może być inna.
Dzięki Data Mesh dane stają się produktem. Mają zespół produktowy, mapę wykorzystania produktu, właściwe zarządzanie i kierunki rozwoju. Z punktu widzenia użytkownika oznacza to znacznie lepszą wykrywalność danych, możliwość samoobsługi (tj. dokumentację, przykłady, schematy) i autonomię. Powstają platformy danych, które są zbiorem wzorców, konwencji, narzędzi i infrastruktury do przechowywania i monitorowania zdarzeń. Ułatwia to użytkownikom danych w skupieniu się na celach i pomaga uniknąć silosów danych znanych z przeszłości. Sposób korzystania z danych przez Data Scientists i użytkowników biznesowych odgrywa w tym kluczową rolę. Natomiast z punktu widzenia działu IT zespoły nie muszą decydować o mechanizmach przechowywania danych. Zastosowany model własności danych rozproszonych wcale nie oznacza ich fizycznego oddzielenia. Jest to prawdziwy początek demokratyzacji danych, bez utraty zarządzania nimi przez dział IT.
Rysunek 3: struktura platformy danych
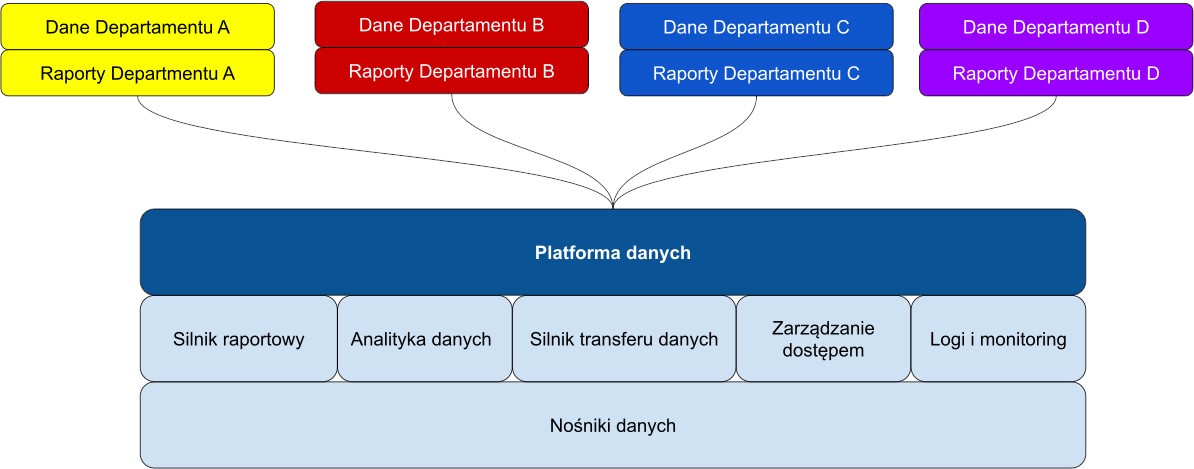
W przypadku systemu danych typu mesh dane są oddzielone, a nie scentralizowane. Jak zatem uniknąć tworzenia silosów danych i ponownej utraty możliwości łączenia danych z różnych dziedzin? Rozwiązaniem jest właściwa standaryzacja komponentów platformy danych i mechanizmów komunikacji.
Przed nowym systemem stoją też wyzwania technologiczne. W świecie mikrousług platforma Kubernetes zdominowała krajobraz i stała się de facto standardem, jednak w obszarze danych sytuacja jest bardziej skomplikowana i właściwie na początku drogi. Dojście do podobnej dominacji w przypadku sieci danych typu mesh zajmie lata, czego przykładem jest historia rozwoju aplikacji dla przedsiębiorstw.
Rysunek 4: hurtownie danych, jeziora danych i sieć danych typu mesh
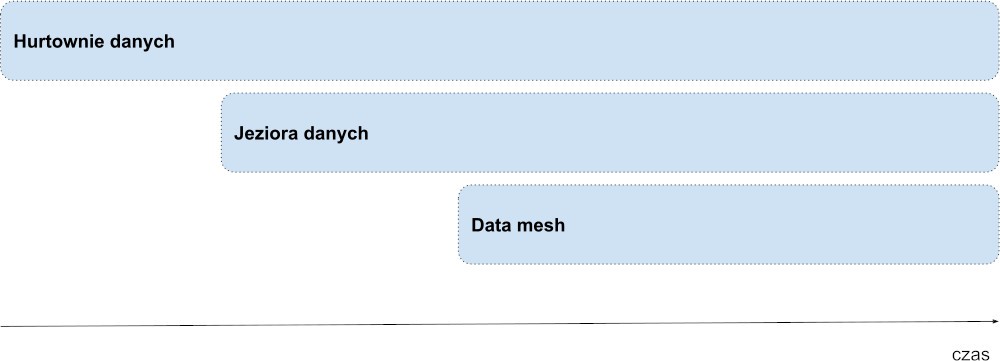
Najnowsza rodzina chmurowych usług, bazujących na danych umożliwia już np.: wykorzystanie istniejących Data Lake do budowy nowoczesnych półautomatycznych hurtowni, tworzenie schematów z danych i wprowadzanie złożonych zapytań. Jednak sieci danych typu mesh, jeziora danych i hurtownie danych będą nadal współistniały.
Jeśli istniejące dziś w firmach jeziora lub hurtownie danych spełniają swoje cele, to trudno byłoby uzasadnić inwestycję w migrację do architektury typu Data Mesh. Niektórzy CIO lub CDO twierdzą nawet, że posiadają architekturę danych typu mesh od lat, tylko nie nazywają jej w ten sposób. Niechętni tworzeniu takich „demokratycznych” platform są też zwolennicy ścisłej kontroli danych przez dział IT. Dlatego najlepszą taktyką na chwilę obecną wydaje się być tradycyjne podejście „jeśli coś działa – nie naprawiaj tego”. Jednak firmy zajmujące się cyfrową transformacją biznesu, takie jak Avenga, monitorują trendy i eksperymentują z podejściem typu Data Mesh w nowych obszarach. Ich prawdziwą wartość pokaże przyszłość.
Jacek Chmiel jest dyrektorem Avenga Labs (Avenga Data bit.ly/2FHJ7sr). Przy opracowaniu tego tekstu współpracowała Olena Domanska, Lead Data Scientist w Avenga.





